
Nice to meet you, mondayDB architecture
mondayDB is the new in-house data engine we crafted at monday.com. It shifted the entire organization’s data paradigm, and is by far the most challenging and rewarding project I’ve had the pleasure of working on.
In this blog post, you’ll get a glimpse of the complexities we tackled when implementing mondayDB, and a drill-down into the creative solutions we crafted in response.

A word about our world
Let’s align on what monday.com does in a nutshell. If you are familiar with our platform, feel free to skip this section.
We refer to ourselves as a Work OS (Operating System) because we equip our users with a platform they can customize and extend, creating a tailored system to manage and automate any aspect of their work.
The key building block of our platform is the “board”. This is basically a very rich table to manage any kind of data — from tasks and projects through deals, marketing campaigns, and anything you’d need to manage a team or business. Each board has columns, which can contain a range of things from basics like text, numbers, or dates to more complex types like a person, team, tag, or even files and formulas. We offer over 40 types of columns, and our users enjoy the freedom to filter, sort, or aggregate just about any column combination, each with its own logic for such operations. For instance, if you filter by person, you can do so by their email, name, or even the team they’re a part of.
On top of the data stored in our customers’ boards, we offer robust features like collaboration tools, sophisticated dashboards, customizable forms, docs, and complex automations. There are also endless integrations or apps offered by developers through our Apps Marketplace. The possibilities are essentially boundless with products and workflows developed on our platform — you could literally build an endless number of products on it (even a refugee camp system).
You mentioned DB, what was that about?
Let’s break it down. Until a while ago, when a user landed on their board, we threw all the board data right into the client (usually a web browser running on a desktop computer).
This approach played a major part in shaping a remarkable product. Our users could perform all sorts of crazy operations on their data, like filtering by anything (we have dozens of different column types, each with a unique structure and accordingly, filter logic), sorting by anything, aggregating by anything, and even joining data across various boards. On top of that, the data was mutable and constantly being updated by other users.
So yes, it was super powerful, but this approach had obvious limitations. First and foremost, the client is limited in its resources. Depending on the client device and board structure, it started to struggle and finally, crashed after a few thousand items (“table rows” in monday.com terminology). If we really pushed it, we could handle up to 20k items. Beyond that, it was game over.
Something clearly had to change. So we decided to move everything to the server side, allowing the client to receive only a subset of items in pages as they scrolled. It was easier for the client but not so trivial for the backend.
Just take a moment to appreciate the requirements our DB would have to address:
- Unlimited tables
- Schemaless tables
- Filter by anything (without knowing that “anything” in advance)
- Sort by anything (again, knowing nothing in advance)
- Aggregate by anything (you got it, not knowing…)
- Dynamic values via formula (= user-defined function)
- Joins
- Low latency
- Horizontal scaling
- Pagination
- Data freshness (inserted data available immediately to queries)
- Hybrid mode (same logic had to be executed on the client for small boards)
- Table level permissions (not allowing anyone to see any board)
- Item level permissions (not allowing anyone to see any item)
And, of course, all that happiness had to be reliable, resilient, fault-tolerant, and all of the other fancy words.
Have you ever encountered so many requirements for a database?
Crafting our own DB, seriously?!
As fun as this might sound (or not), no one really wants to reinvent the wheel. Plenty of battle-proven databases are out there, so the first step we took was to explore our options.
This probably deserves its own blog post, but trust me, we explored many of them, including traditional RDBMS databases with partitions (think MySQL instance per account with a dedicated table per board), ElasticSearch, analytical databases like Apache Pinot, ClickHouse or Apache Druid, and a wide range of NoSQLs like CockroachDB, Couchbase, and more.
Eventually, we found that none of these options completely met our requirements. We don’t say this lightly; we met some of the teams that develop these tools, and they agreed that their databases weren’t designed to handle our specific use case. The reasons varied from our data being mutable, our requirement for numerous tables, not knowing in advance what users would want to filter, and many more.
That said, we noticed a few “small” companies had encountered a similar dilemma. Guess what? They built their own thing. Porcella by Google, Husky by Datadog, and Snowflake Elastic Warehouse are a few examples. So we read all their whitepapers and adopted many of their key concepts with adaptations to what we needed to just get things DONE.
Concept #1: Columnar storage
In a traditional RDBMS such as MySQL, the row is king, and all the row data is stored together on a disk as an atomic unit. While this setup works smoothly when accessing all the data from that row, it’s less efficient when carrying out operations like filtering a specific column. This is because you’d need to pull all the table’s data unless you had prepared a column index in advance (which is something we can’t do without prior knowledge of the schema or queries).
A columnar database, on the other hand, slices the data vertically by column. What this essentially means is that the values of each column’s cells get stored together on the disk as an atomic unit.
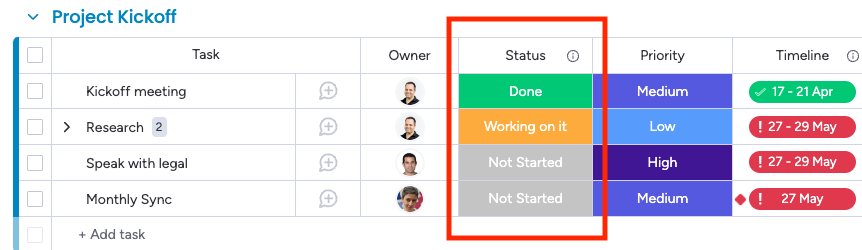
To understand the reasoning behind that idea, visualize the following table from the perspective of a traditional “row store” and contrast it with a “columnar store”:
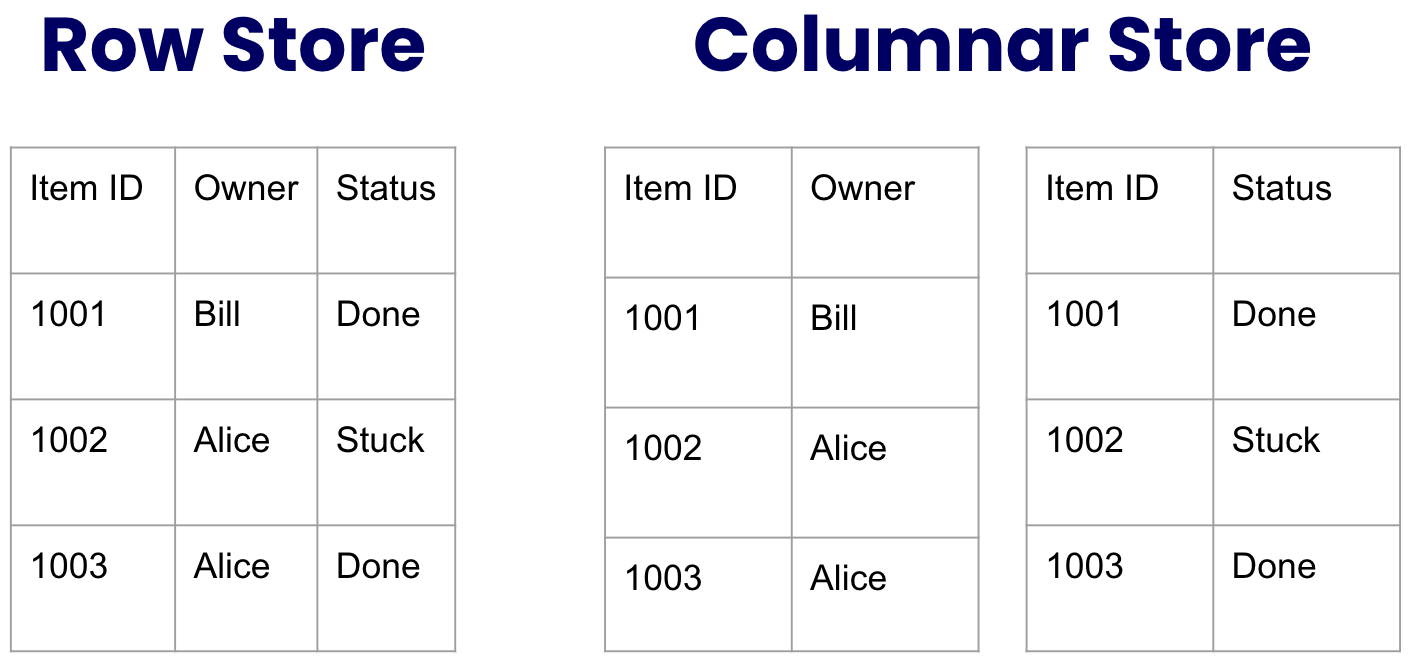
An immediate downside that stands out is that we would have needed to store more data for the columnar store, as the item ID had to be repeated for each cell value. However, this issue is considerably less problematic when we realize that the data is highly compressible, especially when the column displays low cardinality, meaning we have limited repeating values.
That said, the advantages are massive. Consider a standard query on our board, typically involving 1–3 columns. To understand which items meet the filter conditions, we’d only need to fetch a mere fraction of the actual data involved in the filter. Furthermore, as many of our columns are quite sparse, even if the Board is extensive, the data you’d need to retrieve and process could be relatively small.
Lastly, the columnar structure opens up tons of optimization opportunities. Be it compressed data or pre-calculated metadata that can boost up operations. Here’s an example: for a column with low cardinality, we can prepare the item IDs for each unique value ahead of time. This means carrying out filters by those values would take virtually no processing time.
Concept #2: Lambda architecture
As mentioned, we store all the column’s cells together as a single atomic data unit. It implies we can’t fetch or update a single cell separately. So, what’s the process for updating a single cell in our columnar structure?
- Fetch the entire column’s cells data.
- Find and then update the specific cell data.
- Re-write the entire updated column’s cells data.
Oh, and to prevent any race conditions from multiple concurrent updates, it’s necessary to lock writes during the update.
But let’s face it, constantly fetching and re-writing an entire column for each single cell update is not only impractical, but it could also be disastrous as we have thousands of cell updates every second.
Lambda architecture to the rescue. Not to be confused with AWS lambda functions, it was invented by the big data industry to enable you to pre-calculate in advance query results on your data offline. This means queries are executed fast in runtime. The main advantage is that it still serves fresh data recently ingested after the last offline pre-calculation has occurred.
We divide our system into three components:
- Speed layer — contains only recently changed data
- Batch layer — contains all the past historical data
- Serving layer — serves queries by merging the speed and batch layers’ data in runtime
data flows from speed to batch layer. This is handled by a scheduled offline job flushing the data, and building the metadata and other heavy pre-calculations along the way.
Zoom in a bit, we utilize Redis as our speed layer storage, and Cassandra as our batch layer storage. Both of those storages are treated as a straightforward key-value store, where the key corresponds to the column id and the value is the column’s cells data.
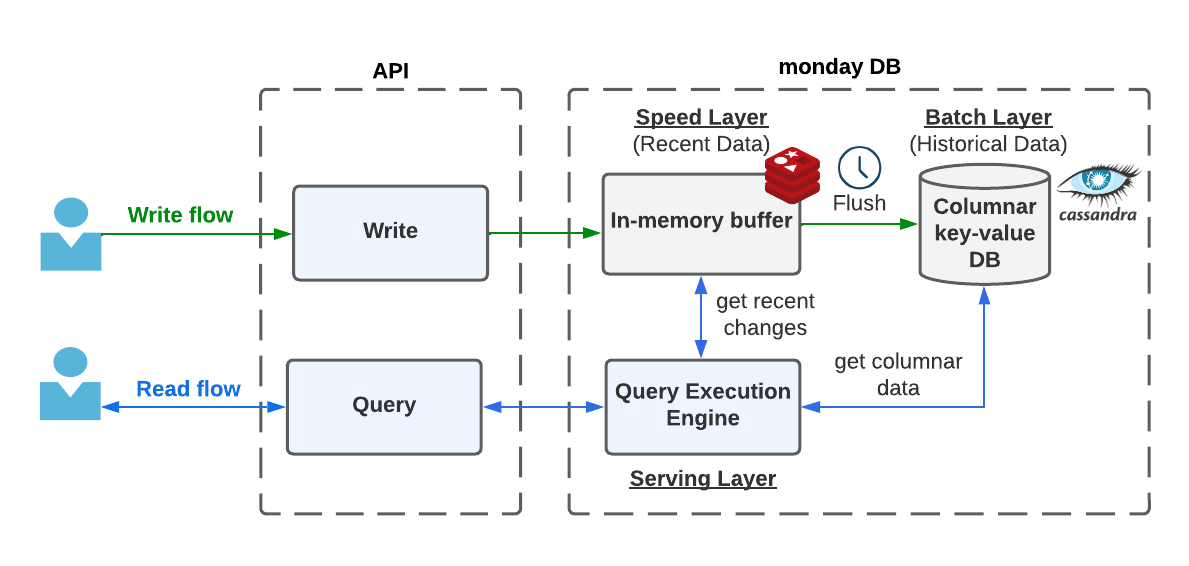
Let’s go over the update flow for a single cell again.
- We store the cell value in our speed layer storage.
That’s it. No locks. As fast as it can get.
Over time, we accumulate more such minor updates. In the background, when we have accumulated enough, or at scheduled intervals, we then:
- Fetch the entire column data from the batch layer.
- Fetch all the accumulated updates from the speed layer.
- Merge.
- Re-write the updated column data to the batch layer.
- <Imagine here all sorts of pre-calculations for read optimizations>
When a user wants to filter by a column, we have the serving layer fetch data from both layers, merge it, and carry out the requested filtering, sorting, or aggregation.
What have we gained?
- It solved our column fetch/re-write problem.
- Recently updated data is available immediately for queries.
- In the background, we can take the time to pre-calculate metadata, indexes, views, compactions, and more.
- Data mutations are super fast.
- No locks involved.
Before we move on, I need to confess: I mentioned that we store the entire column data on a disk as a single data unit. The truth is, we break down large columns into smaller partitions. This aligns with best practices for Cassandra, our batch layer storage, to avoid oversized partitions. This has also paved the way for many optimization opportunities, such as parallel query execution across partitions, partition caching with invalidation for updated ones, skipping fetch/re-write for unchanged partitions, and more.
Concept #3: Separate storage from compute
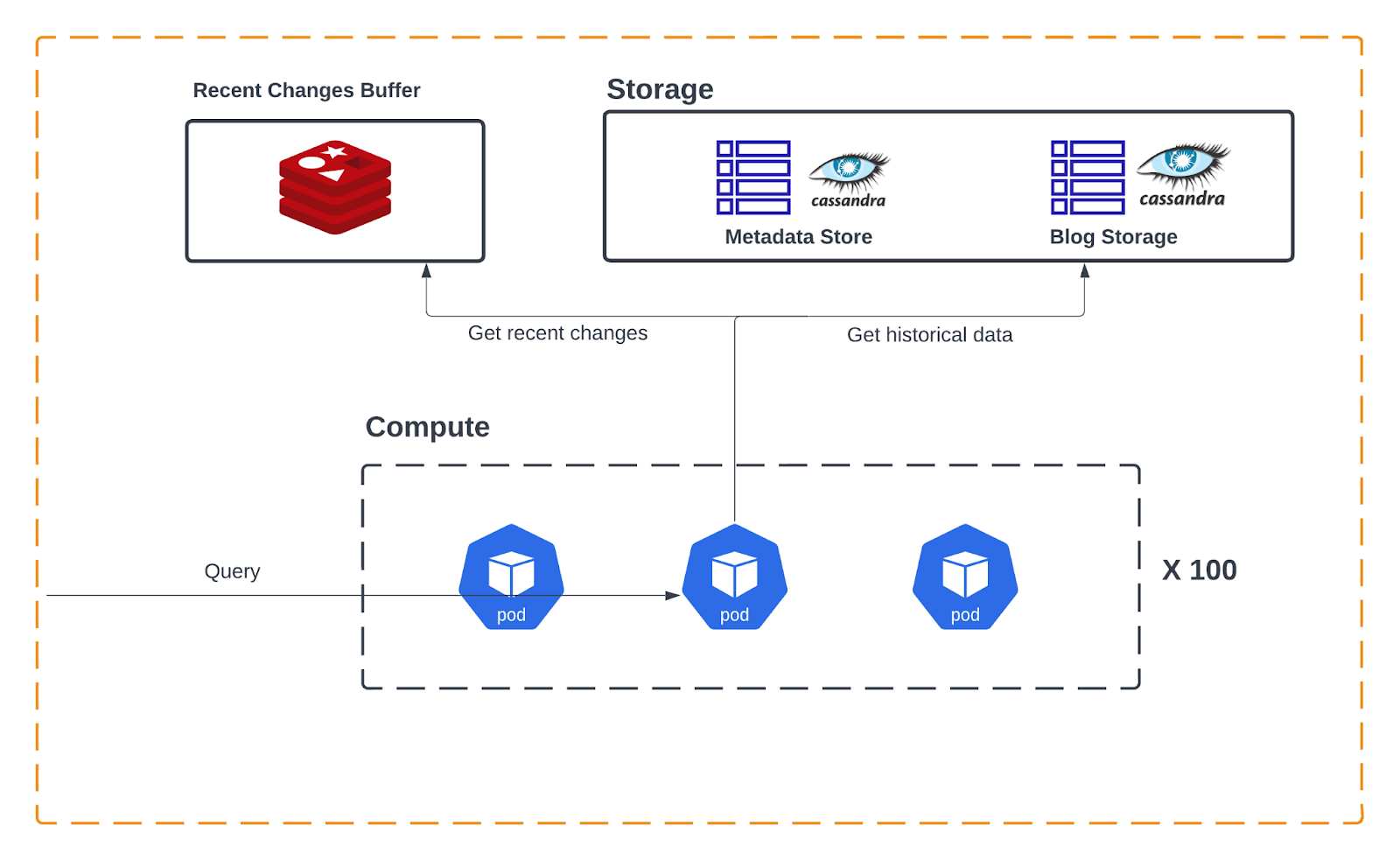
Our system’s nature is that its throughput is dynamic throughout the day. Most of our clients are located in the US time zone. This results in a significantly higher throughput during typical US business hours.
In addition, queries are very volatile. Sometimes you experience a spike of small queries, and at other times, you have fewer but more intense and heavy queries. Some queries require a lot of storage, while others require a lot of computational power. Plus, let’s not forget that data continues to grow and pile up over time, without always maintaining a clear correlation between the data and the queries that process it.
The bottom line is we want our architecture to be elastic. When we need more computational power (CPU) for heavier queries or during peak hours, we want to scale up processing servers. And similarly, we want to be able to scale our storage layer to meet our data capacity demands, separated from any data processing considerations.
Our architecture offers precisely that. Our batch layer is our storage layer and can be scaled independent of our servers engaged in executing query logic, and those servers also scale independently.
So you filter efficiently… then what?
Okay, so we developed this incredible system that can handle multiple filter conditions and tell us what items satisfied those conditions. What’s next? How could we return all the data to the user? How could we enable pagination over that data?
Those are out of the scope of this particular post, but to give you just the gist of it, this is the basic flow:
- A query is executed with the above architecture, narrowing down the item IDs meeting the filter conditions.
- The item IDs are stored on fast temporary storage.
- We generate a unique Query Response ID assigned to that query result.
- Based on the specific page requested by the client, we take the next N item IDs and fetch all their data from our dedicated items store. Note that this isn’t columnar storage — it’s a regular row store, which is incredibly efficient when it comes to fetching complete rows using specific IDs
- We return the items to the client, together with the Query Response Id
Consider the Query Response ID as a snapshot of the data — a moment frozen in time. When a user scrolls further down, that ID is piggy-backed to the backend, which then just slices the next page and fetches the subsequent batch of page items’ data.
The beauty of that approach is that we don’t need to re-execute the query on every page the client requests. Plus, the client can skip by specific offset without having to go over all the items below that offset (imagine a user hitting the “end” key and us instantly fetching the final page).
In addition, if the client wants to go over all the board data through API, they can fetch it page by page without having to worry about mutations applied between each page request, which is very hard to maintain.
However, this approach isn’t without its drawbacks. For instance, how would the user know how to render the page to simulate a lengthy scrollbar? Or figure out what offset to skip when they scroll quickly? And how could they update the view with live mutations by others since the last snapshot?
Those are excellent questions (+1 to myself), but they really deserve their own blog post.
Did it work?
Oh yeah. The entire data paradigm of our company has been shifted, and we are just starting to gather the fruits of it. We’re already seeing significant improvements in board loading times, particularly those of large ones. Let’s peak at one of our monitors:
Board (> 5k items) p99 loading time
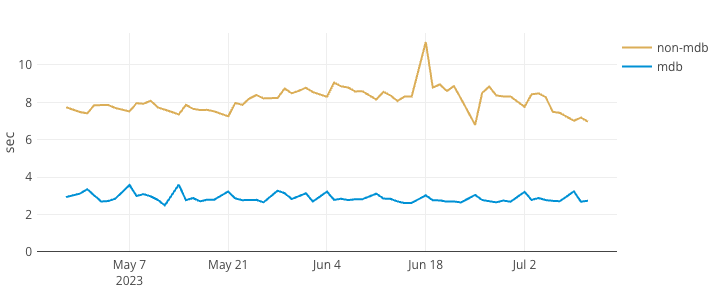
Side-by-side comparison with vs without mondayDB
What’s next?
It’s a long journey as every component of the system needs to adapt to handle only subsets of the data using pagination, rather than having all data readily available to the client. We’ve implemented it for boards, but we have many other components such as our mobile apps, API, views, dashboards, and docs. Furthermore, we now need a more intelligent client that can function in hybrid mode. This ensures that small sets of data can still operate exclusively on the client side, retaining its unbeatable in-client performance without sacrificing its benefits for larger boards.
Our current approach has served us well so far, but there’s substantial room for improvement and lots of optimizations yet to be implemented. To name a few, we have many in-process executions we can parallelize, and we could considerably benefit from adding pre-calculations to generate metadata, indexes, and optimization structures like Bloom filter, among others.
As mentioned earlier, we have dozens of different column types, each one with its unique filter, sort, and aggregation logic. It’s all JavaScript, encapsulated in a shared package between our client and backend so it can run in hybrid mode. Accordingly, our engine is also JavaScript all the way down. We chose this direction to streamline our efforts, even though it’s no secret that JavaScript may not be the optimal choice for a high-performance system.
Looking ahead, we’re weighing up our next moves. We might refactor some of our logic to be executed with highly-performant tech such as DuckDB. We might take advantage of columnar formats such as Arrow and Parquet. We may even refactor our logic using Rust language as a side-car or dedicated microservice. I’m very excited about the future, and will keep you updated!
Our journey has just begun.


