
mondayDB 3 – Solving HTAP for a Trillion-Table System
We recently transitioned from our MySQL fleet to a specialized columnar database engine. In this article, we will explore the architecture of the new system, the challenges we faced during the transition, and the valuable lessons we learned along the way.
TL;DR
This is the story of how monday.com moved board reads from a shared, row-oriented MySQL architecture to a purpose-built columnar serving layer. This was not a database rewrite for its own sake, but to support our most complex use cases and build the infrastructure for the foreseeable future, supporting millions and millions of items in a flexible dataset. We replaced our MySQL, Cassandra, and Redis fleet with a single, purpose-built system powered by a DuckDB columnar engine. Board loads improved by 5x, large boards by 20x, and aggregations by nearly 50x. Infrastructure costs dropped by 40-60%. We migrated millions of organizations with zero downtime and zero data loss. The architecture we built, per-tenant file isolation, smart routing, always-fresh reads, is now the foundation for our AI contextual layer: text search, semantic retrieval, and RAG, all at the same latency and with the same reliability guarantees.
How We Got Here
Imagine a spreadsheet. Now imagine a trillion of them, each with a different shape, different columns, different types, different sizes. Some have 10 rows. Some have 500,000. Users add columns on the fly, rename them, change their types, delete them, and add relations. The schemas are never fixed. This flexibility is the heart of the monday.com system. It is a huge advantage that allows us to serve hundreds of thousands of tenants and their needs; it is even more important in the age of autonomous agents accessing and shaping data in growing volume and speed. That flexibility is exactly what makes boards useful. It is also what made them increasingly difficult to serve efficiently. The system had to support millions of constantly changing schemas while still making every board feel fast and interactive.
The code data structure that enables this flexibility is what we call a board. A board is a dynamic, user-defined table where rows are items and columns can be anything: text, numbers, dates, status labels, people assignments, formulas, or links to other boards. Over 1M organizations rely on these boards every day for the core aspects of their work, from complex production workflows to CRM, project management, and hundreds of other use cases. From a database perspective, that means every board behaves like its own evolving table, with a schema that can change at any moment.
For years, we stored all of our data in MySQL.Our first answer to that flexibility was MySQL plus JSON. It was simple, reliable, and gave us the schema freedom we needed without forcing every board change to become a database migration. Each item was a single row, with all of its column values stored as JSON within that row. This afforded us the schema flexibility we needed; any board could have any columns, and adding a column was as simple as adding a key to the JSON: no ALTER TABLE, no migration.
This setup worked surprisingly well for a very long time (kudos to MySQL developers). As we grew past 1 million organizations and demand grew for much greater scale and more complex data use cases like reporting, dashboards, and millions of queryable items in a single dataset, the setup started to fray at the seams.
Board loads for large boards routinely took over two seconds. Aggregation queries, sorting, filtering and grouping crawled. Every query had to deserialize the JSON blob for each row, and MySQL could not efficiently index, filter, or sort on values within that JSON. The row-oriented storage format was fundamentally mismatched with our access pattern.
When a user opens a board, they see around 500 rows, but the system reads all columns. That is a wide read, exactly the pattern where row stores suffer most. As they had to read the entire row (including the full JSON blob) even if the user only needed a few columns, and they stored data row-by-row when it was needed column-by-column.
The multi-tenant model made it worse. Over a million organizations shared the same MySQL tables. The indexes were enormous, billions of rows in a single B-tree. Loading a single board meant traversing an index that held data for every tenant on that shard. Disk reads pulled in index pages and data pages from unrelated organizations, wasting I/O on rows that had nothing to do with the query. Memory, and therefore the limited RDS disk, was under constant pressure as different tenants competed for the same cache space. More tenants meant bigger indexes, more random I/O, and higher load on every database instance.
We did the obvious things. Multiple read replicas with tenant sharding to spread the load. ProxySQL for connection pooling and query routing. Partitioning tables to keep index sizes manageable. Each one bought us time, but none addressed the fundamental mismatch; we were still running wide analytical reads on a row-oriented engine that stored everything as JSON blobs in shared, multi-tenant tables.
We needed something different. Not another MySQL optimization. A different architecture.
What Matters First – Results
Here’s what we measured after full rollout.
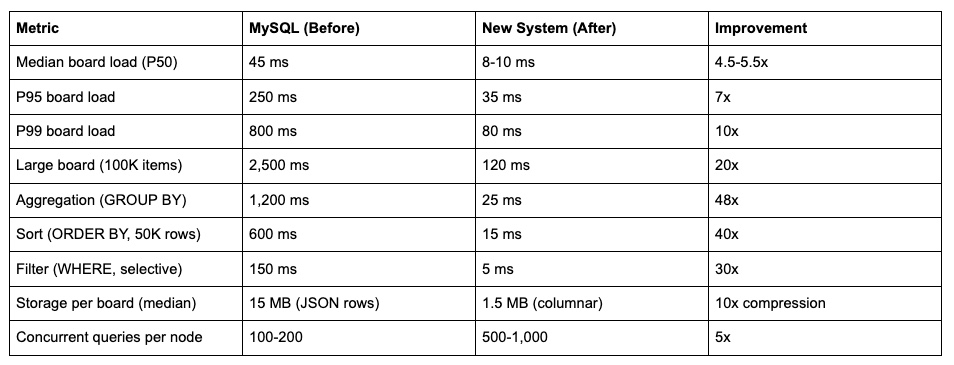
Infrastructure costs dropped by 40-60% compared to the MySQL fleet, while delivering 5-10x better performance. We eliminated the need for connection-pooling middleware, read replicas, and shard-management infrastructure.
The system now serves 100% of board read traffic for more than 1M organizations. Cache hit rates hold steady above 95%. Median WAL sync latency is 3 milliseconds.
Under increasing load, the performance gap widens. MySQL degrades as connection pools saturate and lock contention increases. Our system stays flat because each query operates on an independent DuckDB file with no shared state between queries.
mondayDB 3 – CQRS FTW
We built a complete separation of write and read paths, where the secret sauce for read performance lies in a redundant, soft-stateful serving layer. On top of that, we broke the coupling between storage and compute, enabling our engine to scale indefinitely.
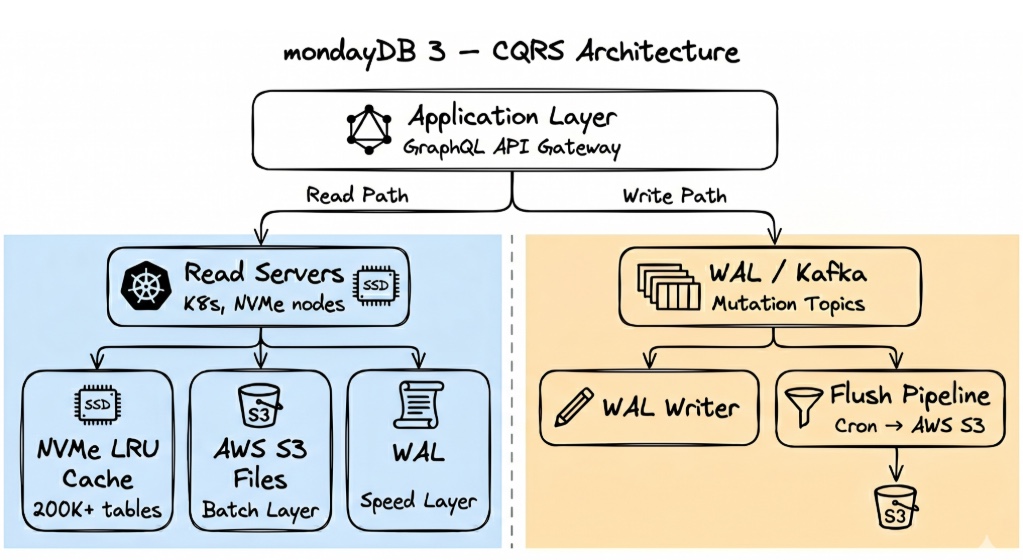
At a high level, mondayDB 3 works like this: durable snapshots live in object storage, recent changes live in the WAL, and serving nodes keep local DuckDB files in sync before each query.
The batch layer stores the complete representation of all data as DuckDB files in object storage. A flush pipeline periodically consolidates WAL entries into these files, which serve as the durable source of truth for cold data.
The speed layer captures real-time mutations through an external WAL. When a user modifies a board, the mutation flows through WAL, Kafka, and the writer, which persists it. Recent mutations become available for read-time merging within milliseconds.
The serving layer is a fleet of Go processes on Kubernetes nodes with local NVMe SSDs. Each node is soft-stateful and essentially acts as a smart read-through cache; any node can serve any board because the source of truth is always S3 + WAL, not the local disk. But the nodes hold the state for performance: each one maintains an LRU cache of over 200,000 DuckDB files, and losing that warm cache incurs higher latency costs until it rebuilds.
The Go layer is intentionally thin: it handles request routing, cache management, and WAL synchronization, but all query execution is delegated to DuckDB’s vectorized C++ engine running in-process. When a read arrives, the node loads the board’s DuckDB file from cache (or rebuilds it from the batch layer), syncs pending WAL entries into the file, and executes the query, all on local RAM and NVMe.
The read and write paths are separate. They share no compute, processes, or local storage. The WAL backend is shared between them, but if the WAL goes down, serving nodes continue serving reads from their last-synced local state. Write-path failures (Kafka lag, WAL backend throttling) do not block read availability. Read-path failures (node crashes, disk issues) do not block write processing.
DuckDB’s single-writer limitation becomes a non-issue here: the only process that ever writes to a DuckDB file is the serving node’s own sync routine, triggered by reads.
DuckDB integration details
Each board maps to a DuckDB schema with multiple data points. DuckDB files are attached at runtime with ATTACH ‘…’ AS schema (TYPE DUCKDB, RECOVERY_MODE NO_WAL_WRITES). We disabled DuckDB’s internal WAL because our external WAL handles durability, reducing NVMe write amplification and speeding up attach/detach operations.
The connection pool maintains 4 connection groups, each with 6 threads (24 concurrent query slots per node). Each connection can handle requests to any number of attached databases. We use DuckDB’s Table Appender API for bulk mutations, bypassing the SQL parser entirely to insert operations, which is critical for fast WAL sync.
Dynamic schema evolution is handled transparently: when a WAL entry references a column that doesn’t exist in the local DuckDB table, we issue ALTER TABLE ADD COLUMN on the fly. In DuckDB’s columnar format, adding a column simply creates a new column segment initialized with NULLs; no data reorganization or table rebuild is required.
The Flush Pipeline
The write path has three stages, each running as a separate Kubernetes workload:
Stage 1 – Job Generation (CronJob, hourly): Acquires a distributed lock, scans a Redis set tracking boards with pending changes since the last flush, groups partitions by account ID for locality, and publishes flush jobs to SQS with a 10-worker pool.
Stage 2 – Flush Execution (Consumer): Processes jobs from 2 SQS queues (scheduled + priority, 600s visibility timeout). Per partition: acquire lock → sync table from remote (force-download latest S3 snapshot + apply WAL) → validate integrity → optional DB compaction → upload .db to S3 → append audit record → reset the changed-since-flush watermark → publish cache invalidation via PubSub if changes exceeded a threshold.
Stage 3 – Integrity (Consumer): Handles correctness operations across 5 SQS queues: drift detection with auto-fix, full data migration from chunked payloads, column type version updates, partition deletion, and GDPR right-to-erasure (with 1-hour visibility timeout for large account deletions).
The three stages are independent, each scales based on its own queue depth, and together they ensure the batch layer converges toward the WAL state.
The WAL: Our External Write-Ahead Log
DuckDB’s built-in WAL was designed for single-process crash recovery. We needed something very different: a WAL that was distributed (readable from any serving node), durable (mutations cannot be lost), ordered (deterministic replay), and fast (single-digit millisecond reads).
We disabled DuckDB’s native WAL entirely (via the NO_WAL_WRITES pragma) and ran our own distributed WAL.
We built two WAL backends, each optimized for a different cost/performance tradeoff:
WAL for entities requiring strong durability (board items, column values, column definitions). An external WAL writer service consumes Kafka topics partitioned by board ID (ensuring per-board ordering), and persists each mutation as a WAL item with a monotonically increasing sequence number. Serving nodes query for entries newer than their last-synced position using QUERY … WHERE seq >:lastSync. Our WAL gives us consistent single-digit-millisecond reads, automatic scaling, and strong read-after-write consistency within a partition. Entries expire via TTL after being flushed to the batch layer. Rate limiting is applied via Redis (3 retries, 1s exponential backoff) to prevent throttling during traffic spikes.
Redis write cache or high-frequency, cost-sensitive entities where sub-millisecond read latency matters more than multi-day durability. Retention is 48 hours. This is sufficient to cover multiple flush cycles and provide an operational recovery buffer.
The consistency model is straightforward: read-after-write consistency within a board partition. Anyone who modifies a board and immediately loads it will see the change. Cross-board reads (like dashboards aggregating multiple boards) are eventually consistent, typically converging within 500 milliseconds.
The external WAL turned DuckDB’s biggest limitation into an architectural advantage. By managing writes outside DuckDB, we got complete write/read separation, independent scaling, and failure isolation, things that would have been much harder with a traditional database’s built-in write path.
Read Path: Sync-Then-Query
The core algorithm is deceptively simple: before every query, sync the local DuckDB file with the latest WAL entries, then execute the query. Seven steps, typically completing in under 10 milliseconds.
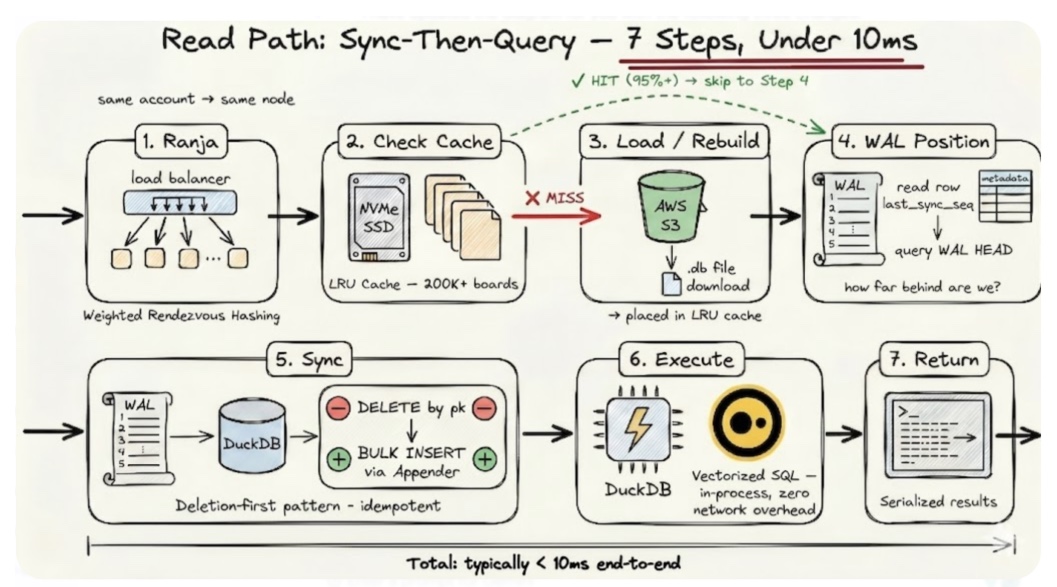
Step 1: Route. Our load balancer uses the account ID to route the request to a specific serving node. Sticky routing means repeated requests for the same board hit the same node, maximizing cache hits.
Step 2: Check cache. The serving node checks its NVMe-backed LRU cache for the board’s DuckDB file. On a hit (95%+ of steady-state requests), we skip to Step 4.
Step 3: Load or rebuild. On a cache miss, the file is downloaded from object storage, or a new one is built from batch files. Then it’s placed in the LRU cache.
Step 4: Determine WAL position. Read the last-synced sequence number from the local file. Query the WAL for the current head
Step 5: Sync. Fetch and apply any pending WAL entries to the DuckDB file. We use a deletion-first pattern: for each mutation, delete matching rows by primary key, then bulk-insert the new data via DuckDB’s Table Appender API. This simplifies update logic to delete-then-insert and is fast for the typical case of tens to hundreds of pending mutations.
Step 6: Execute. Run the SQL query against the now-current DuckDB file. In-process, zero network overhead, vectorized execution.
Step 7: Return serialized results
The sync step is idempotent; the deletion-first pattern means applying the same WAL entries twice produces the same result. This guarantees correctness across retries, cache rebuilds, and multi-node scenarios.
Each serving node runs a connection pool of 24 concurrent DuckDB query slots (4 groups × 6 threads), with a 2-second hold timeout. Multiple boards are synced concurrently – up to 50 goroutines in parallel, with a hard cap of 500 tables per query. This concurrent sync is critical for dashboard queries that fan out across dozens of boards simultaneously.
Queries arrive as POST /data/query with an SQL template containing {{placeholder}} tokens mapped to {entityName, subPartitionKey} pairs via a tablesMetadata field. This allows a single query to span multiple entity types and partitions while keeping the SQL generic.
Smart Routing for Cache Affinity
Once reads depend on warm local files, routing is no longer just load balancing. It becomes part of how the database delivers predictable latency.
A cache that stores 200,000+ DuckDB files per node is only useful if requests for the same board consistently land on the same node. We built a custom routing layer to make this happen.
The algorithm is not consistent hashing. We use Weighted Rendezvous Hashing (Highest Random Weight): For each request, every node computes score = hash(node_id, tenant_id) * weight, and the request goes to the highest-scoring node. All nodes compute the same result independently; no central coordinator needed.
What makes this powerful:
- Capacity-aware weights are dynamically adjusted based on real-time node capacity, quantized into 5 discrete levels to prevent oscillations. Capacity information piggybacks on heartbeat messages, just 2 extra bits, zero additional network overhead.
- Hedged requests handle slow nodes gracefully. If the primary node does not respond within 500ms, a hedge request goes to a secondary node. Whichever responds first wins.
- Peak EWMA-based load balancing, as each tenant has a replication factor. The routing layer load balances based on observed tail latency (moving windows of p95 latency based on t-digest) and the outgoing queue size.
- Minimal blast radius on failure. When a node goes down, each surviving node picks up only 2-9 additional tenants. We handle a 2,000,000:1 ratio between the largest and smallest tenants gracefully.
- 65 million routing decisions per second on commodity hardware.
The architecture was formally verified using TLA+ to ensure correctness under all failure and partition scenarios. In production, our capacity-aware SIEVE cache eviction policy achieves a 3-6x improvement in hit rate over standard LRU by prioritizing “native” tenants (those hashed to this node) over “guest” tenants (overflow from failed nodes).
Entity Plugin System
The system was designed from day one as a multi-entity platform for monday.com, not as a single-purpose board data store. It supports 10+ entity types through a JSON-driven plugin architecture. Each entity type is defined by a configuration file specifying:
- Base schema — fixed columns (IDs, timestamps, state)
- Dynamic schema fetcher — how to discover user-defined columns at runtime (HTTP call to a schema service, or static config)
- WAL strategy — which WAL backend to use
- Transformers — structure transformer (raw WAL payload → DuckDB row layout) and value transformer (type coercion, NULL handling, JSON flattening)
- Integrity handler — validation logic for drift detection
Adding a new entity type requires only a JSON config file — no core engine changes. The standard lifecycle (Kafka ingestion → WAL → sync-then-query → flush → S3) is handled entirely by the framework. This has enabled onboarding new entity types in days rather than weeks.
Zero Downtime Migration
Building the new architecture was only half the challenge. The other half is the migration process.
Migrating more than 1M organizations from MySQL to a completely new data engine without downtime was an 18-month effort. The strategy was conservative, incremental, and reversible at every step.
Feature flags controlled everything. Read source (MySQL, new system, or both), write path (MySQL, Kafka, or both), entity scope, rollback, all toggleable per account, per entity, per board. Instant rollback to MySQL was always one flag flip away.
We ran dual-read validation for months. Every board load query was executed against both MySQL and the new system, with results compared automatically. Discrepancies were logged with full context. We uncovered dozens of subtle issues: NULL-handling differences, Unicode normalization mismatches, floating-point precision gaps, sort-order ties and time zone edge cases. Each one was fixed before cutover.
Rollout was per-account, starting with our own internal accounts, then beta customers, then small accounts, and finally enterprise accounts. Risk assessment considered board size, column complexity, feature usage, and customer tier.
When the system detects an unexpected result or an unhandled exception during a query, it automatically fails over to the old pipeline. These exceptions don’t just get swallowed; they flow into a separate pipeline that routes them to R&D for automatic investigation and fixing.
The actual cutover was anticlimactic, by design. Because we had been dual-writing throughout, the new system’s data was already current. Cutover was a feature flag flip: no data transfer, no schema migration, no restart. Dual-write mode was maintained for 30 days post-cutover, keeping MySQL as an instant rollback target.
We flipped more than 1M organizations from MySQL to a completely new database engine, and the only thing users saw was faster boards.
Lessons Learned
After 18 months of building and migrating, here are the five lessons that shaped our thinking the most.
1. Work with your engine’s constraints, not against them
DuckDB’s single-writer limitation initially felt like a dealbreaker. We considered workarounds, write buffering inside DuckDB and multiple files per board with union queries. Instead, we stepped back and asked: what if we don’t write to DuckDB from the write path at all?
The external WAL approach that emerged is cleaner than any workaround would have been. It gave us complete read/write separation, independent scaling, and failure isolation. The constraint forced a better architecture.
2. Local storage caching changes everything, and Ranja makes cold starts manageable
NVMe-backed local caches with 200,000+ DuckDB files per node deliver incredible performance. Nodes do restart a few times a day, and the system handles it well. The key is Ranja, our custom routing layer that we developed specifically for this architecture. For each query, Ranja sends the request to 2 nodes simultaneously. This helps absorb latency spikes during reboots and ensures that even when a node comes back with a cold cache, the secondary node serves the request with no user-visible impact.
We don’t do pre-warming today, but the system is built for it if we ever need it. We chose a fixed-scaling model over autoscaling because the simplicity and predictability outweigh the cost of slight over-provisioning.
3. Dynamic schemas are harder than you think
Users change column types, create columns with reserved-word names, delete and re-create columns with different types, and use empty strings as column names. Every one of these is an edge case that will break something. We built a comprehensive test suite of schema evolution scenarios and still occasionally discover new ones.
4. Migrate conservatively; dual-read validation is worth the investment
The months we spent in dual-read mode, comparing MySQL results against our new system for every query, caught issues we never would have found through testing alone. Unicode normalization differences, floating-point precision gaps, sort-order ambiguities – these are the kinds of bugs that only surface at scale with real data. The confidence this gave us made the actual cutover uneventful, which is exactly what you want.
5. Purpose-built beats general-purpose
We did not build a general-purpose database. We built a data system optimized for one specific workload: wide reads over moderate row counts with dynamic schemas and frequent aggregations. By narrowing our scope, we achieved performance and cost characteristics that would be impossible with any general-purpose solution.
The best database for a given workload is often not a database at all; it is a carefully engineered system that aligns storage format, execution model, and caching strategy with the application’s actual access patterns.
Why We Chose DuckDB
While we were considering writing our own execution engine from scratch, we evaluated several open- sources embedded solutions and server-based engines, which led us to DuckDB. DuckDB won decisively for our workload.
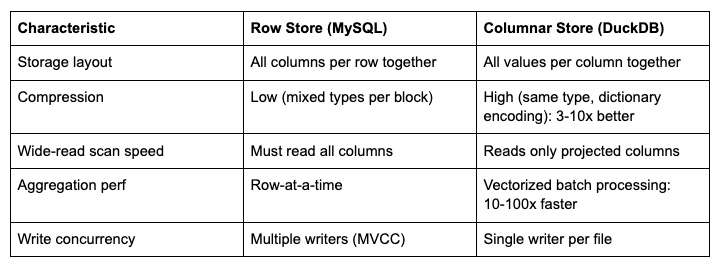
The insight was simple: our workload is analytical, not transactional. Reads vastly outnumber writes. Queries scan wide rows across many columns. Sorting, filtering, and grouping are first-class operations in our UI. This is textbook columnar territory.
It was very easy to integrate simple SQL with any language, no C++ code was needed. It included all parts of a DB: query parser, query planner, very scalable architecture, custom UDFs, and much more.
The first POC worked for us after 10 minutes.
In-process execution. DuckDB runs as a library inside our process, not as a separate server. No network round-trips. No connection handshakes. Query execution begins the instant we call it.
Attach/Detach per tenant. DuckDB lets you attach and detach database files dynamically at runtime. This maps perfectly to our multi-tenant model: one DuckDB file per board, attached when needed and detached when evicted from the cache – file-level isolation between tenants with zero server-process overhead.
Vectorized execution. DuckDB processes data in batches of 2,048 values, exploiting SIMD instructions and cache-aligned memory access. For our aggregation-heavy workload, this delivers order-of-magnitude speedups over row-at-a-time processing.
Our users are, unknowingly, running analytical queries every time they open a board. They sort, filter, group, and paginate, all operations where columnar engines dominate. We were running an analytics workload on an OLTP database.
The tradeoff? DuckDB only supports a single writer per database file. For a system handling thousands of concurrent writes per second across hundreds of thousands of boards, this sounds like a dealbreaker. It turned out to be the constraint that shaped our best architectural decision.
What’s Next
The architecture we built to serve board reads turns out to be the same architecture you need for AI context retrieval. Think about what we already have: per-board file isolation gives every board its own knowledge boundary – sync-then-query guarantees fresh context.
When an AI agent needs to reason about a board, it gets the latest state, not an embedding generated hours ago from stale data. Ranja co-locates a board’s structured data and its embeddings on the same NVMe node, so context retrieval is a local operation with no network hop. The entity plugin system lets us add new data types, embeddings, search indexes, and knowledge graphs through JSON configuration, no engine changes required.
We are building MDB3 into a contextual layer for AI. The same read pipeline that serves a board load in 10 milliseconds can serve a text search, a semantic retrieval, or a RAG query with the same latency characteristics. The Lambda Architecture separates expensive AI computation (embedding generation, index building) into the batch path, keeping the serving layer fast and predictable. Read/write separation means AI workloads do not compete with user mutations. And the multi-tenant design, one file per board, sticky routing, and cache affinity, scales naturally to hundreds of thousands of tenants without the noisy-neighbor problems that plague shared-index architectures.
The pattern matters more than the engine. File-per-tenant isolation, sync-then-query freshness, co-located caching with smart routing, these architectural properties hold whether the underlying engine is DuckDB, a vector store, or something else entirely.
We see MDB3 evolving from a board data engine into the infrastructure layer that powers text search, semantic search, reasoning, reranking, and retrieval-augmented generation across our platform. The same architecture that replaced MySQL is now positioned to become the foundation for AI.
The shift from a general-purpose row store to a purpose-built contextual engine was the most impactful infrastructure decision we have made. And the timing matters: agents demand even more flexibility and scale than human users ever did. A user might run a few queries against a board in a session; an agent reasoning over the same board can issue dozens or more, with shapes you cannot predict in advance, filtering on one column, grouping by another, joining across boards, scanning for semantic neighbors, all within a single chain of thought.
Thank You.
We would like to acknowledge the amazing core team that made this possible: Idan Davidi, Liran Brimer, Yossi Alufer, and Yuly Roberman. Their technical leadership and dedication were instrumental in building the backbone of mondayDB 3.0.
And a huge THANK YOU to the DuckDB team.
This post describes our production architecture as of early 2026. We plan to share deeper dives into specific subsystems, the WAL, the routing layer, and the migration framework in future posts.


