
Managing Infrastructure at monday.com with Ensemble
Evolution of monday.com
A decade ago, monday.com was initially launched as a monolithic platform, hosted in a single region on AWS.
In order to improve performance, resiliency, and compliance, we made the decision to transition to a multi-region architecture. As a result, we deployed the platform in two additional regions. In addition, we continued to develop more and more microservices to break down the monolithic architecture.
These changes allowed us to improve the overall performance and reliability of monday.com.
Managing Infrastructure as Code
With the microservice-based architecture, each application functions as an independent component with its own infrastructure, including RDS, Redis, SQS, S3 buckets, and more.
We manage all the infrastructure with Terraform – a widely used Infrastructure-as-Code tool for provisioning and managing infrastructure resources. Terraform’s high-level configuration language is used for defining the desired resources, and Terraform maintains the applied configuration in a state file.
At the time, resource definitions were scattered among our many application repositories, and each of the resources, within a given AWS region and environment (staging or production) had its own state backend for the purpose of isolation.
The Terraform commands were being run manually by the Infrastructure team from their local machines.
Infrastructure Management Challenges
Using Terraform in this manner became challenging and problematic for the following reasons:
- Making changes across different applications was difficult – When we needed to make changes that affected multiple applications (like upgrading module versions), we had to change code in many different repositories.
- Lots of manual work – Due to the way we organized directories, making changes to the same resource for an application in different environments and regions required a lot of manual effort.
- No enforced code review – We couldn’t ensure that changes were only applied after a code review. Human mistakes could have easily led to production incidents.
- Difficulty in reviewing changes – With many modules and abstractions, it was hard to understand from the code how exactly the infrastructure would be affected by a PR without running
terraform plan. - Drifts between the main branch and Terraform state – There were cases where code was applied but wasn’t merged to our main branch or the other way around. This caused the main branch to not accurately represent the actual state of the resources and could have led to Infrastructure personnel overwriting each other’s changes.
- Execution environment & security – Running Terraform commands locally required having all dependencies installed and AWS credentials stored locally.
Solution Requirements
A few months ago, we began searching for a better way to manage and deploy our infrastructure. Here are the key thoughts we had in mind:
- Automated remote workflow – First and foremost, we understood that we had to eliminate the need for manual Terraform operations, performed from our local machines. Many of the following benefits follow from this decision.
- Restrict local permissions – Take away local admin permissions so no one could apply configuration locally. This way, changes could only be deployed after a code review and the main branch would always accurately reflect the infrastructure’s actual state.
- Centralized infrastructure configuration – Since the infrastructure team handles all infrastructure management, it would be better to have a single repository that holds all infrastructure configuration. A single repository is easier to maintain and set up CI/CD on.
- Isolated states for safety – Keep Terraform states isolated as a best practice to reduce potential risks or mistakes’ impact (“blast radius”).
- Enforce plan review on PRs – To ensure proper review and validation of all states changed in a PR, all changes should be visualized and there should be a process of blocking merges until all changes are reviewed and approved.
Taking Infrastructure as Code Management to the Next Level
The first thing we did was migrate all Terraform code from the application repositories to a single centralized Terraform repository. This consolidation made our code easier to manage and maintain.
Next, we searched for a tool for deploying Terraform infrastructure changes remotely. We had the following requirements in mind:
- Auto-discovery of Terraform files – Auto-detection of projects* that have been changed in the PR without the need for explicitly specifying their location in a configuration file.
- Comprehensive PR-centric plan visualization – PR-centric view of all changed project resources in a clear and easy-to-review format. Simply put, all the Terraform “plans” included in a PR should be reviewed as a whole, in a single view, without switching between numerous project-specific views.
- GitHub integration – PR merges should be blocked until all project changes are approved.
- Security considerations – As the tool would require high privileges to manage everything infrastructure-related, it had to comply with our internal security best practices and policies.
* At monday.com, each directory that includes a Terraform backend file (state configuration) is referred to as a “project”.
We looked at various existing managed Terraform CI/CD products and general-purpose CI tools. However, none of them provided a complete solution that fully met our needs.
After careful consideration, we decided not to compromise on our full requirements and as a result, we chose to develop our own internal tool. This way, we could tailor it to match our specific needs, integrate it directly into our internal developer platform, and ensure it would work seamlessly in our infrastructure management process.
Disclaimer: It’s essential to acknowledge that alternative approaches exist for each of our requirements. While our decision to develop a custom tool was driven by our desire to meet precise specifications, organizations with different requirements may find suitable off-the-shelf solutions that align with their needs, potentially saving time and resources.
Building Ensemble, our in-house Terraform CI/CD tool
We chose to call the tool Ensemble, inspired by musical ensembles, with components related to relevant terms.
Since our technological stack primarily consists of TypeScript services running on Kubernetes, we felt comfortable choosing these technologies for the development of Ensemble.
Ensemble automates our most widely-used Terraform flows – plan, apply, and destroy and is based on a step-by-step workflow that is triggered by PR events on our centralized infrastructure repository.
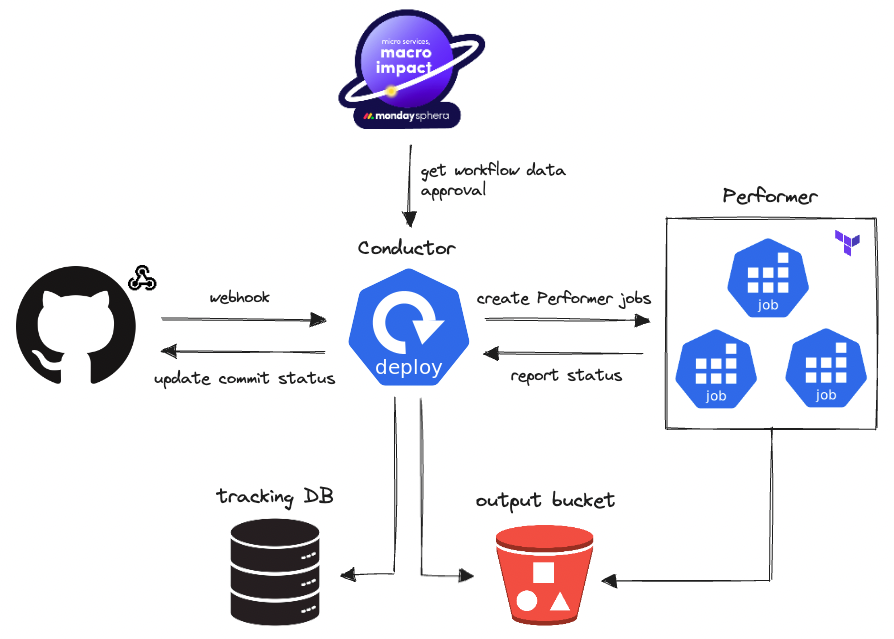
Ensemble consists of the following components:
- Conductor – This component is a Kubernetes Deployment that handles GitHub webhooks and automatically detects all changed projects in a PR. It then triggers the Performer job for each of these projects.
- Performer – This component is a Kubernetes Job that is responsible for running Terraform commands for a specific project. It can work in either a “plan” mode, which generates the execution plan, or an “apply” mode, which applies the changes.
- GitHub integration – This component updates the GitHub commit status in a PR and prevents merges until all changes are approved by the reviewer.
- User interface – The UI provides a visual representation of the workflow steps (Terraform commands) and displays plan outputs, making it easy to review changes. The UI was developed as part of our internal developer platform called sphera.
We chose to split the Conductor and Performer into two services, for separation of code changes, deployments, and more. Running the Performer as a Kubernetes Job (as opposed to a Deployment for instance) makes sense because it’s designed to execute commands until completion, in addition to being able to leverage the Kubernetes scheduler for utilizing our idle compute resources.
Deep Dive into the Workflow
- GitHub PR creation triggers the Conductor using a webhook.
- The Conductor, which is installed as a GitHub App, receives the webhook and creates a GitHub commit status on the PR, showing a brief description of its current state, and blocking the PR from being merged.
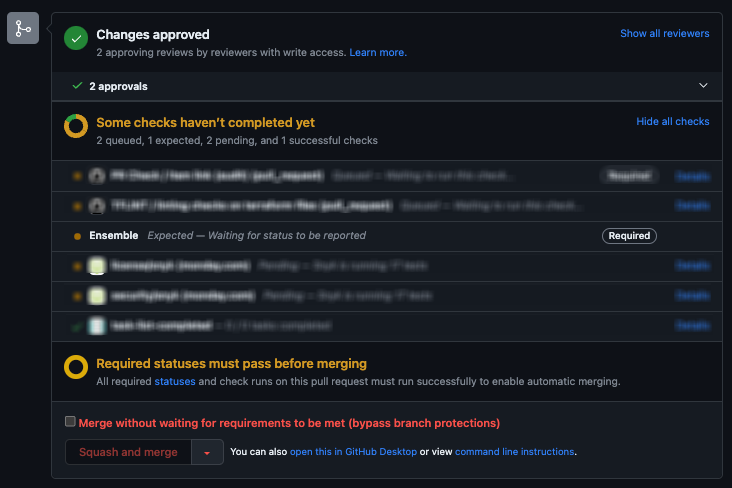
- The Conductor automatically detects the changed Terraform projects based on the changed files in the PR. It then creates a Kubernetes job (a Performer) for each project.
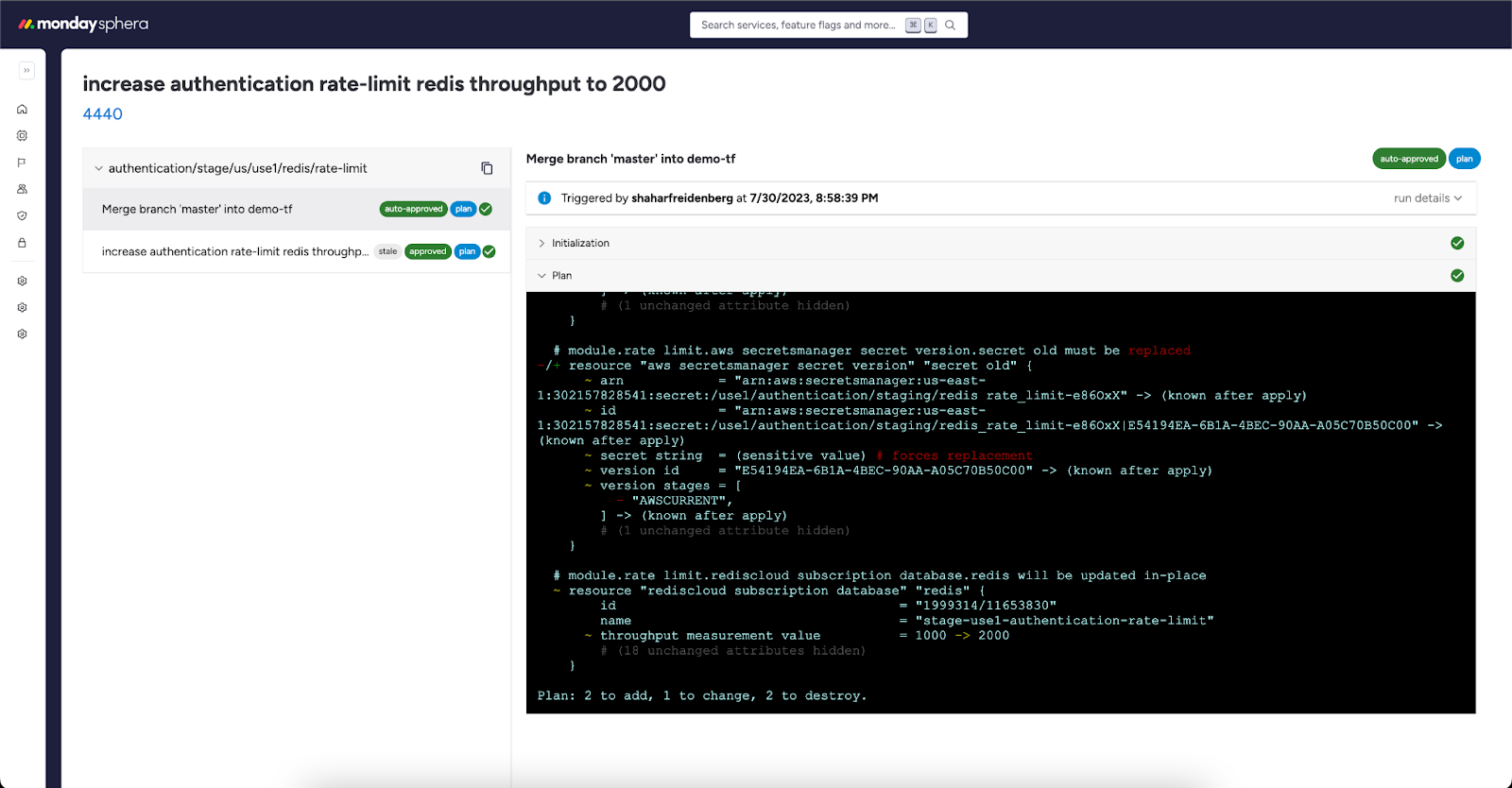
- A Performer runs Terraform commands for each specified project in “plan” mode. It executes
terraform initfollowed byterraform plan, and saves the command outputs to an S3 bucket. - Each Performer reports the status of its Terraform commands to the Conductor in real time, and the Conductor stores it in its database. For example, when a
planbegins, if it succeeds or fails, etc. With the workflow’s current status tracked in the database, we can visualize it using the commit status and on a dedicated page for the PR in Sphera.

terraform plan on each modified project- Once the plan step ends, the Conductor updates the PR’s commit status to “Pending – Waiting for your approval”. The reviewer can click on it to access the matching page in sphera and review the plan outputs.

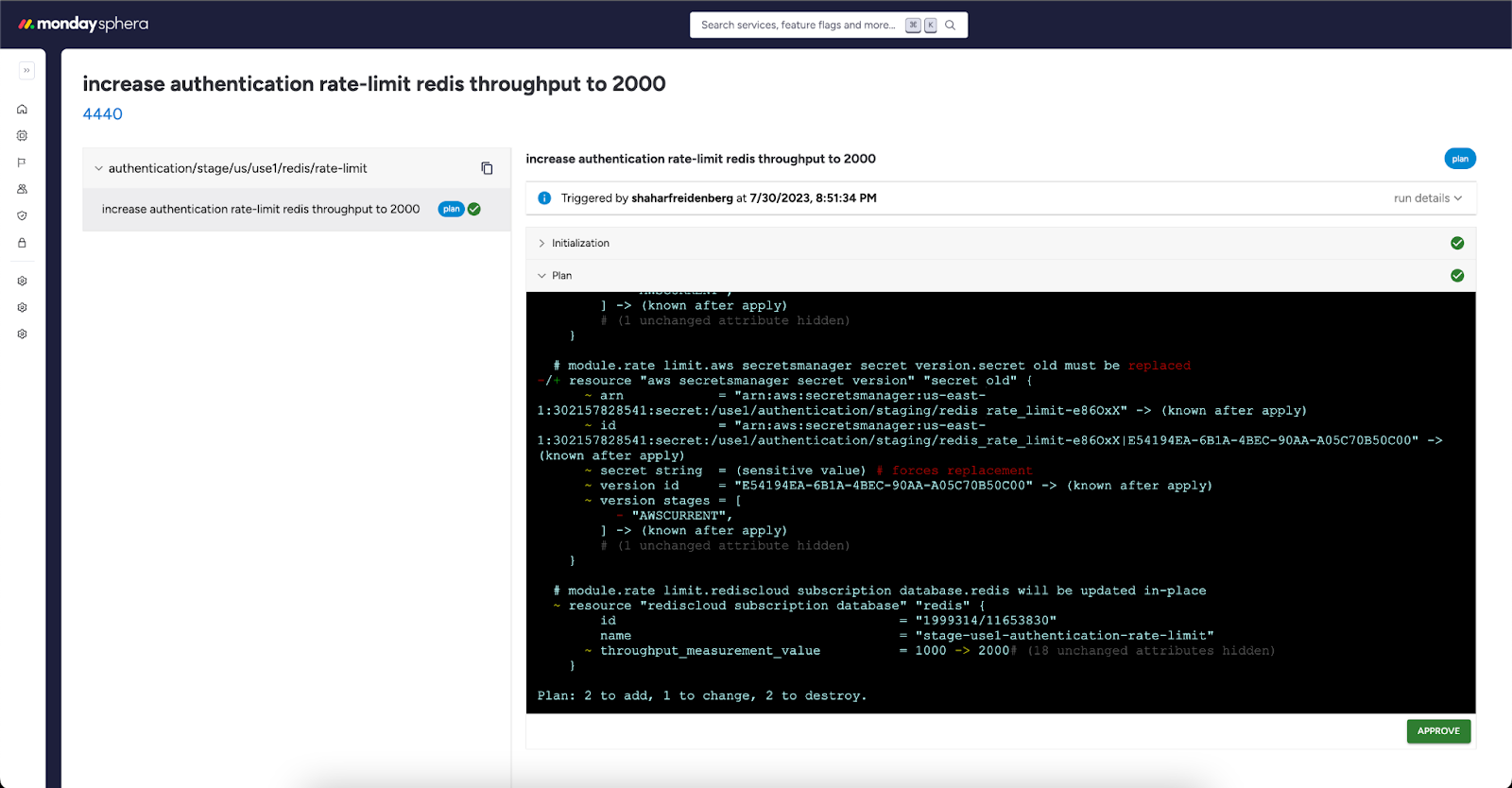
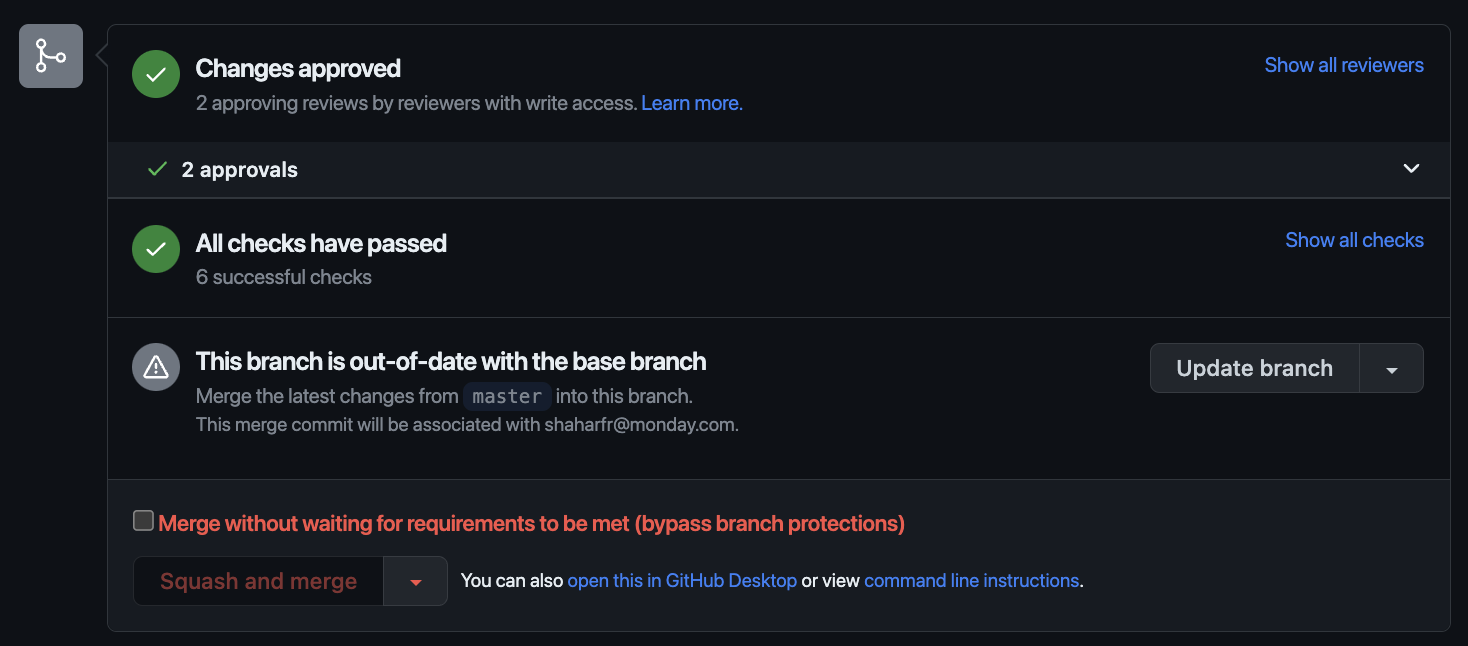
- The reviewer should approve the planned output for all changed projects in Sphera. This sends an API request to the Conductor, which updates the PR’s commit status to “approved”, allowing the PR to be merged.
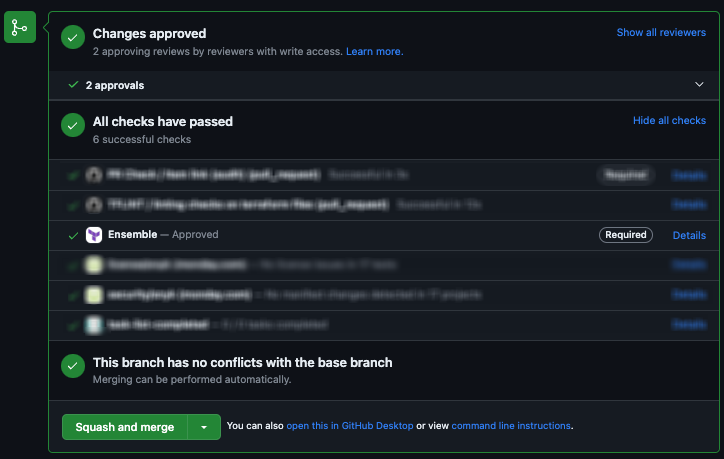
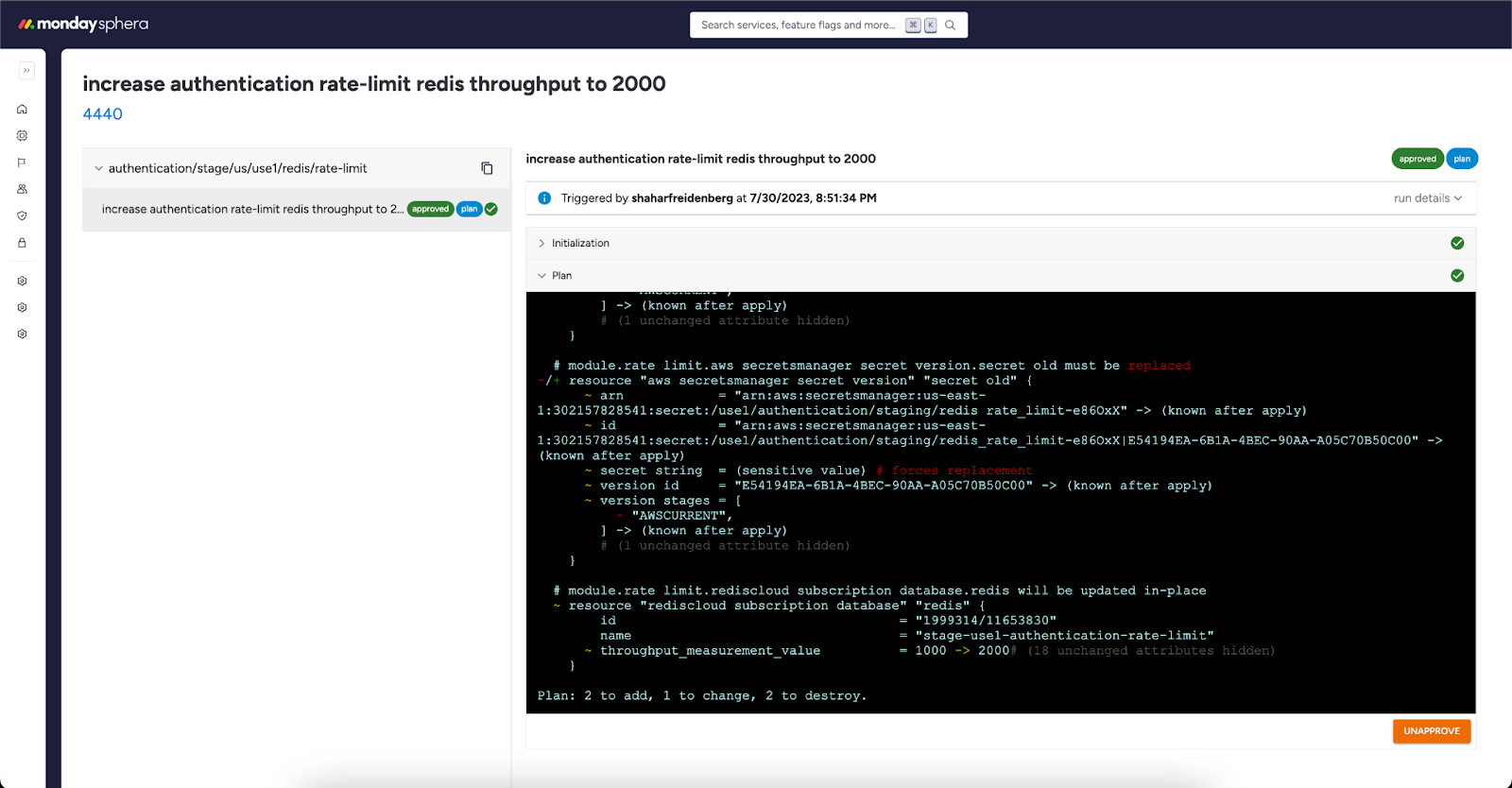
- If any additional commit occurs after approval, the webhook retriggers the Conductor which in turn launches Performer jobs and checks if the new plan matches the last approved plan. If it does, meaning no state changes occurred since the last plan was approved, the Conductor auto-approves the new plan, and the PR can be merged. If the plan differs, the PR’s commit status changes back to “pending approval”, blocking the merge. This approach of rerunning
terraform planaffords the greatest degree of safety in a highly dynamic environment, while auto-approval serves as a way to reduce the unnecessary human involvement that would otherwise come with manually approving the same project again and again.
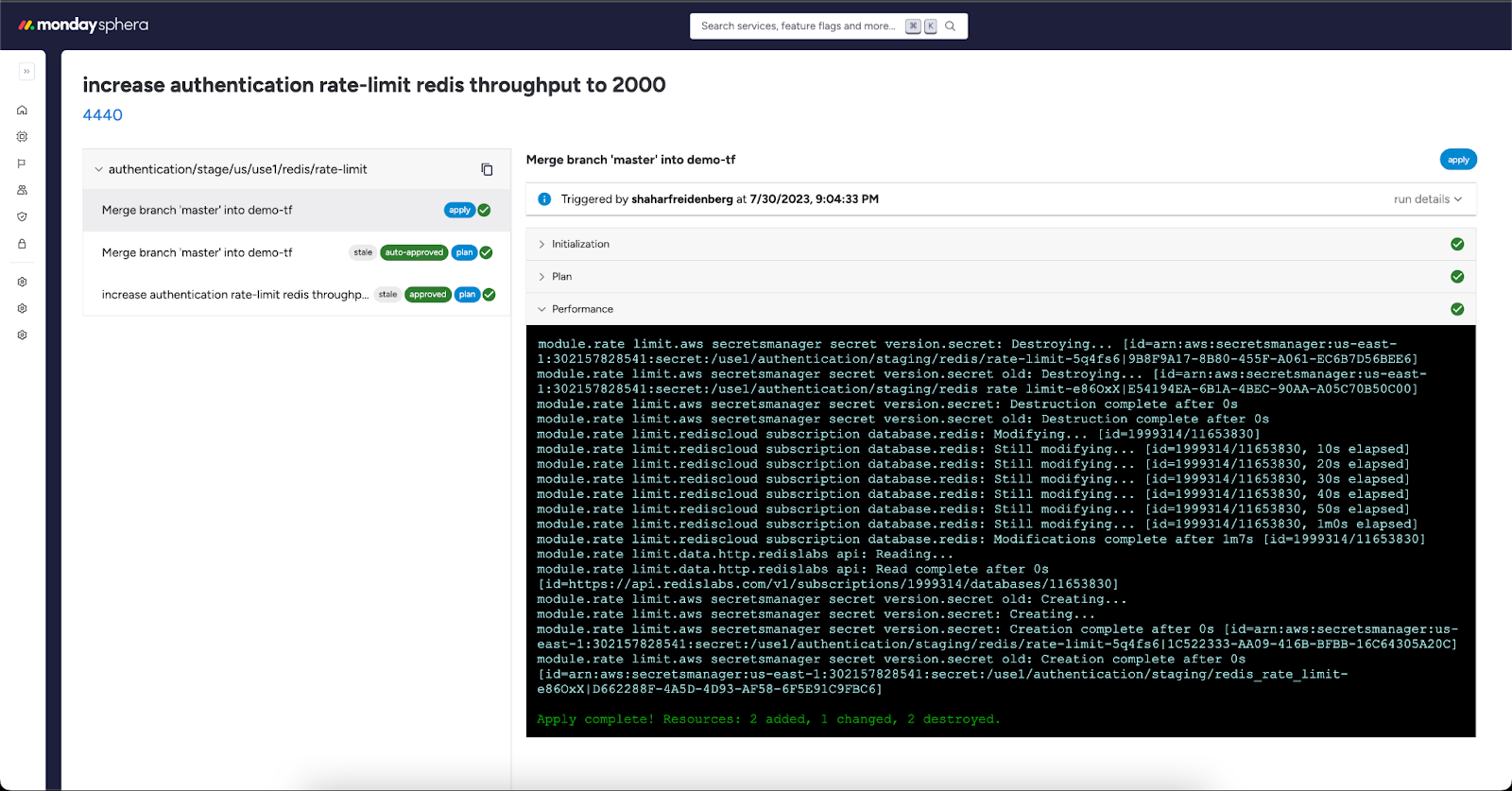
- A merge event triggers another webhook to the Conductor. The Conductor creates a Performer job in “apply” mode for each changed project. The Performer executes
terraform initfollowed byterraform apply, based on the last approved plan, ensuring no unreviewed changes are applied.
- The GitHub infrastructure repository enforces commit rebasing before the merge to the main branch to ensure the planned output used in the apply command aligns with the latest code. This eliminates the need for any other locking mechanism.
Ensemble Architecture
Conclusion
By developing and adopting our in-house tool, we’ve achieved better control over our infrastructure management, reduced manual efforts, and enforced stricter code review practices. This solution has been tailored to meet our specific requirements and seamlessly integrate with our existing infrastructure management processes. As a result, we now enjoy a more efficient and reliable workflow for managing and deploying infrastructure changes at monday.com.


