
Unlocking Performance –
A Journey of Scaling Up with Elasticsearch
At monday.com, we rely on Elasticsearch to meet various needs. It supports our clients’ search requirements across account entities, particularly on our dedicated Search Everything page. Additionally, we utilize Elasticsearch for aggregating data in complementary areas.
One notable instance is our Inbox page, where users can see updates across their boards –
However, as our client base expanded rapidly, we encountered challenges. The Inbox view was implemented a few years ago and the indexing method became inefficient with the growing number of clients, leading to latency in read performance. To address this, we formed a team of three developers with expertise in Elasticsearch and our platform. Together, we devised a strategy to upgrade our cluster and optimize our indexing approach.
KPIs
These are the KPIs we used during the project, which provides a comprehensive overview of the success and impact of our Elasticsearch migration on system health, performance, and incident management.
1. System Health Increase: Increase Elasticsearch service availability to 99.99%.
2. Performance Improvements: Improve the query response by at least 2x
During the migration process, we aimed to run the migration itself with zero downtime and zero incidents along the way.
The data migration process
1. Cluster Creation
The process began with the creation of a new Elasticsearch cluster on AWS’s managed OpenSearch service, leveraging our existing knowledge and troubleshooting tools.
This cluster served as the foundation for our optimized setup, providing a stable environment for the migration process.
In addition, we decided to go with AWS Graviton to maximize our performance and reduce our monthly costs.
2. Creating 200 Indices
Elasticsearch operates using indices, each of which is divided into shards functioning as independent units for the database. When querying a one large index, we might conduct searches and aggregations across our entire customer database. Alternatively, creating an index for each customer could lead to significant management overhead and potential computational costs.
To optimize our indexing approach, we decided to create 200 different indices, where each shard will contain, on average 10gb of data.
We went one step further and divided our accounts between the indices so that all data of a particular account would be stored in the same index, and each index could hold data of several accounts..
We implemented a strategy where the indexing and querying were targeted to an index name based on the account ID modulo 200. This meticulous division allowed us to distribute data efficiently across indices, ensuring optimal performance and preventing latency issues.
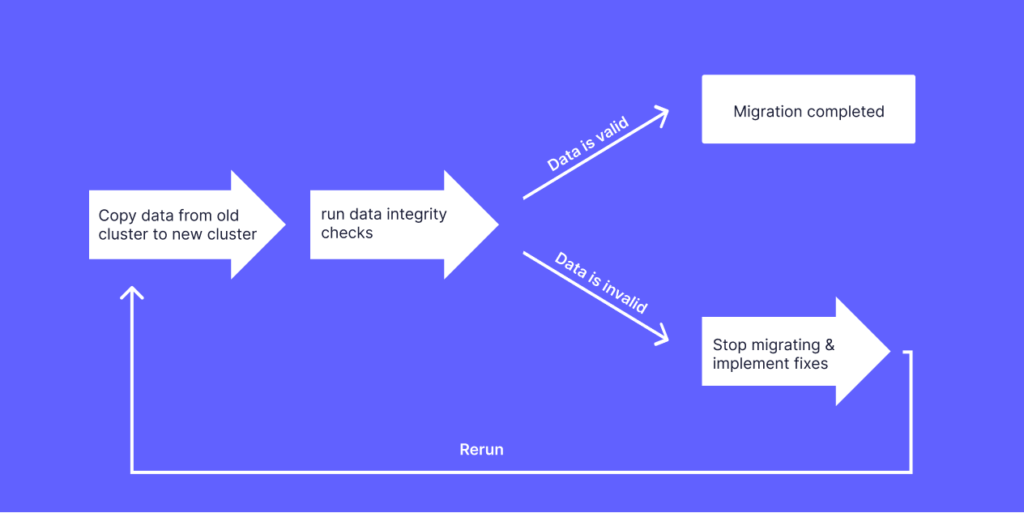
3. Data Integrity and Performance Checks
Ensuring the integrity of the migrated data was paramount. We implemented a robust data integrity check mechanism to validate the accuracy of the migration. This involved comparing search results from the old cluster and the new one. By running queries concurrently on both clusters, we could verify that the data returned matched, confirming both a successful migration without data loss, and that our query logic, that was now copied to the new cluster, is still correct. Additionally, we measured the time taken for results to be retrieved from Elasticsearch, providing valuable insights into performance improvements.
4. Throttling and Optimization
During the migration, we implemented throttling to manage the data transfer process effectively. Throttling allowed us to regulate the migration speed, ensuring that the platform’s CPU utilization remained stable and preventing any adverse impact on ongoing operations. This careful management of resources was crucial to maintaining a smooth user experience.
5. Iterative Fixes and Adjustments
Despite our meticulous planning, we encountered challenges along the way. The migration process involved iterative fixes and adjustments. As issues arose, our team promptly identified and resolved them, ensuring that the migration remained on track. This iterative approach allowed us to adapt to unforeseen circumstances and maintain the integrity of the migration process.
Some iterations required data manipulation while migrating, which made the migration more tricky, but was worth it because the end resulted with much more efficient cluster.
We implemented, iterated through solutions and ran the final migration within 2 weeks.
The process strategy
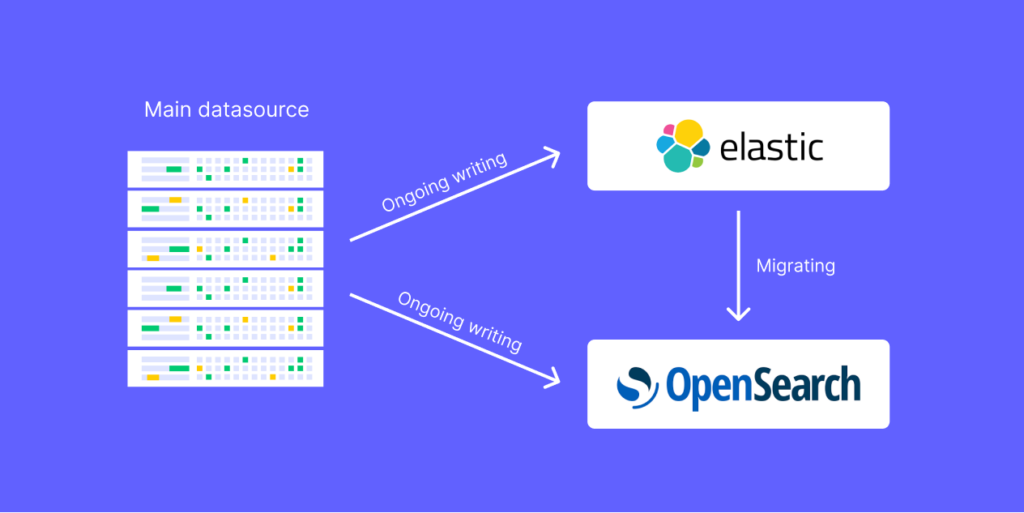
We had a goal to support a live migration while the platform was running. We had to ensure the continuous writing and queries to Elasticsearch persist, while simultaneously progressing with the migration to Opensearch.
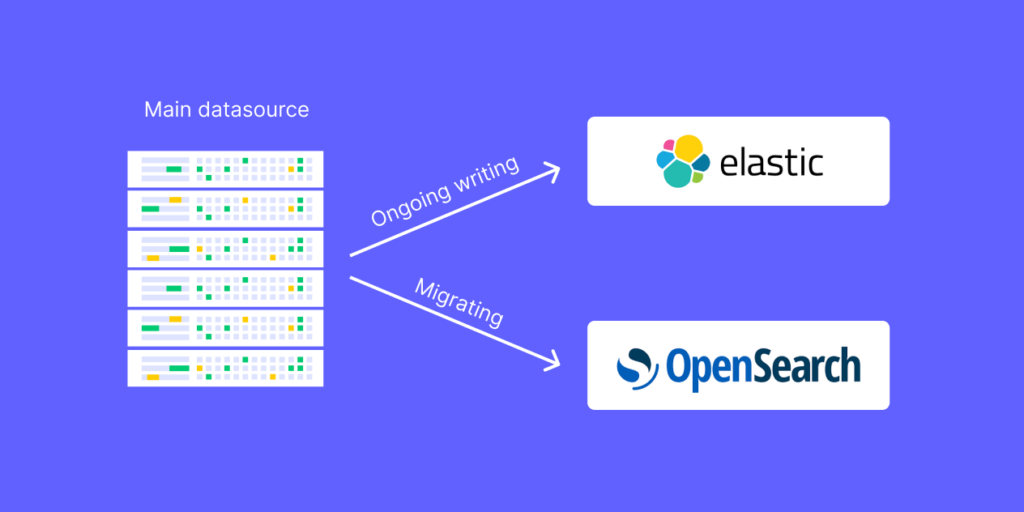
To be able to support that, the order of actions is critical. If we would simply start with migrating the data we would quickly run into a loop of chasing our own tail of having to re-run the migration for live data that was indexed while the previous migration was running. To avoid that, we actually first started with indexing the ongoing data to both clusters (old and new), and only then, when we were sure that ongoing data is kept up to date, we ran the migration to backfill all historical data.
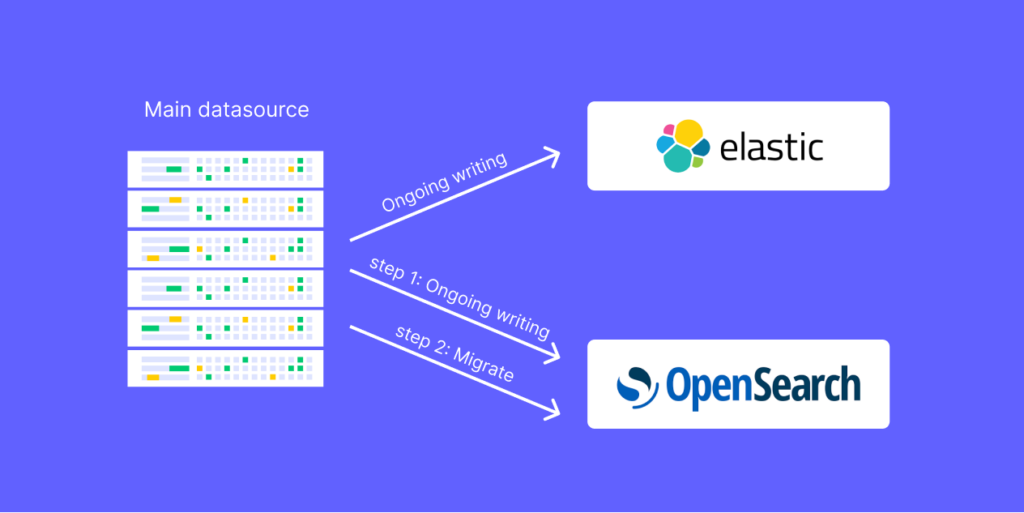
A pitfall that we found on the way –
We started copying the data from our relational database. The intent behind that was that that is our source of truth, and we wanted to fix corrupted data, if exists. We began calculating the time it would take for the migration process to complete. We found out that even though we ran the script in various parallel jobs, the completion of the migration would take months to complete, and we wanted to achieve the goals much faster.
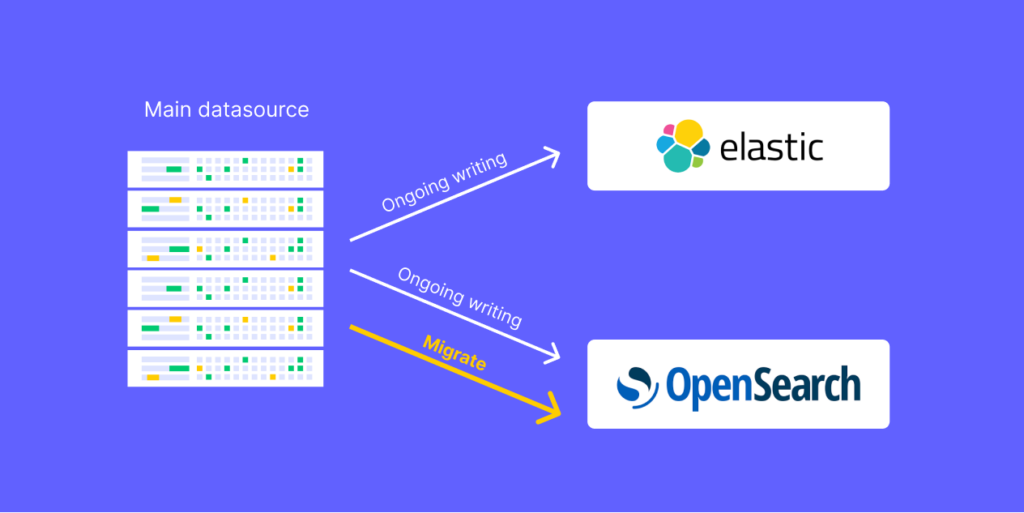
Having said that, we saw that running the migration from one cluster to another, while manipulating our documents’ data to our needs, is 12X faster!
With this solution, we completed the data migration within 4 days(!), copying 2 TB of data from one cluster to another, while throttling the migration process – slowing down the process during critical daytime hours to prevent CPU utilization from reaching high peaks but “pushing the gas pedal” when there’s relatively low traffic on the platform and we could speed up the process.
Data integrity and performance checks
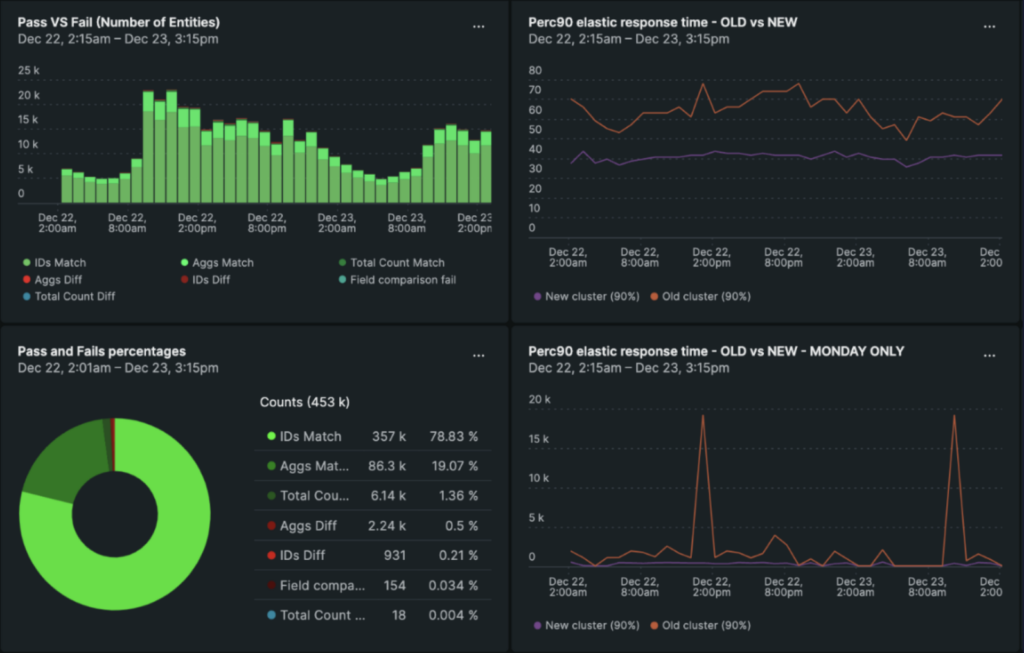
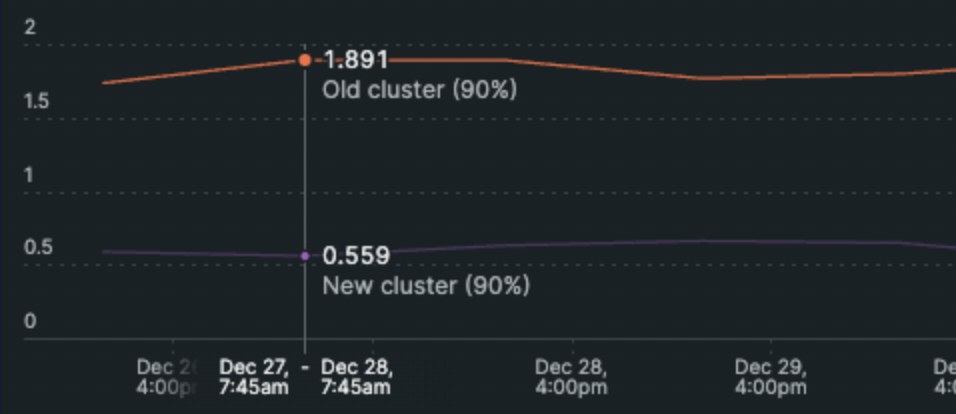
In order to verify that our migration script is working well, we created a data integrity check. When users query Elasticsearch, we first return the results to the client directly from the old cluster, but then in the background, we start a job of running the query again on the new cluster, and comparing the actual documents that were returned from the old and new clusters. This give us the indication of whether our data was migrated successfully and we are querying it correctly
Another win from the data integrity check was the output of the time it took for the result to get back from Elasticsearch.
We presented both the data integrity checks and performance results on a dashboard to easily visualize the difference.
Even though the full migration process took 4 days and everything looked green, it took us several iterations to fix some bugs along the way, as both the migration process and the data integrity checks needed some adjustments.
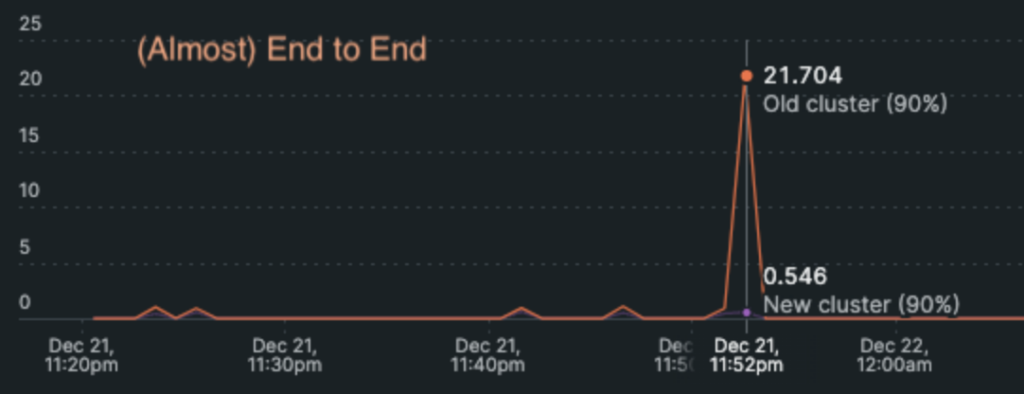
The big impact
The technical win – After 2 weeks of completing the migration and gradually opening it to clients, we kept the old cluster up and running as a fallback while measuring the success of Inbox page loading times and results. We achieved an amazing 3.5X performance boost on average, with a 40X boost in peak times for complex queries, and “heavy” accounts.
The financial savings – We managed to reduce our monthly cost by 70% (!!!) when using AWS Graviton machines.
Our KPIs –
1. System Health Increase: Increased Elasticsearch service availability to 99.99% ✅
2. Performance Improvements: Improved the query response by 3.5X – 40X ✅🔥
Conclusion and takeaways
1. Consider migrating to Opensearch and Graviton, as they are significantly cheaper and more performant options.
2. Begin your data migration process by enabling ongoing indexing to old and new clusters. Only then do that actual migration of backfilling all existing data. This will save you chasing your tail with ongoing updates while the migration is running.
3. Implement precautions such as throttling, pause/resume mechanisms, and a kill switch to prevent cluster overload during migration and ensure a smooth user experience.
4. Perform integrity checks and compare data and query results between old and new clusters to identify and resolve issues, building confidence in the new cluster’s reliability.
5. Implement a code switch that allows you to retrieve results from either the old or new cluster, facilitating a seamless transition. Combined with integrity checks, this approach ensures a smooth switchover process.
6. For future migrations – Consider using Elasticsearch backup snapshots for even faster data migration, while the ongoing index is running in the background.


