
IaC at scale at monday.com with CDKTF
Infrastructure as Code Challenges
monday.com is deployed in a multi-account and multi-region architecture.
With the growth of the platform, we found the way we manage our infrastructure very hard to maintain. This is mainly due to our Terraform directory structure, which includes hundreds of different states, requiring us to run Terraform commands in multiple directories for every single change. Our infrastructure includes application-related resources such as S3 buckets, SNS topics, and SQS queues, and general infrastructure resources such as EKS clusters and networking configuration.
To reduce the manual work (and for many other reasons), we developed Ensemble, our in-house Terraform CI/CD tool. Ensemble auto-discovers code changes in a pull request and then plans or applies the relevant states.
Ensemble did help us move faster in terms of deployment of a change in multiple environments and regions, but with the number of states we have, the development process is still frustrating as multi-account or multi-region modification requires changes in multiple directories and a lot of copying and pasting code.
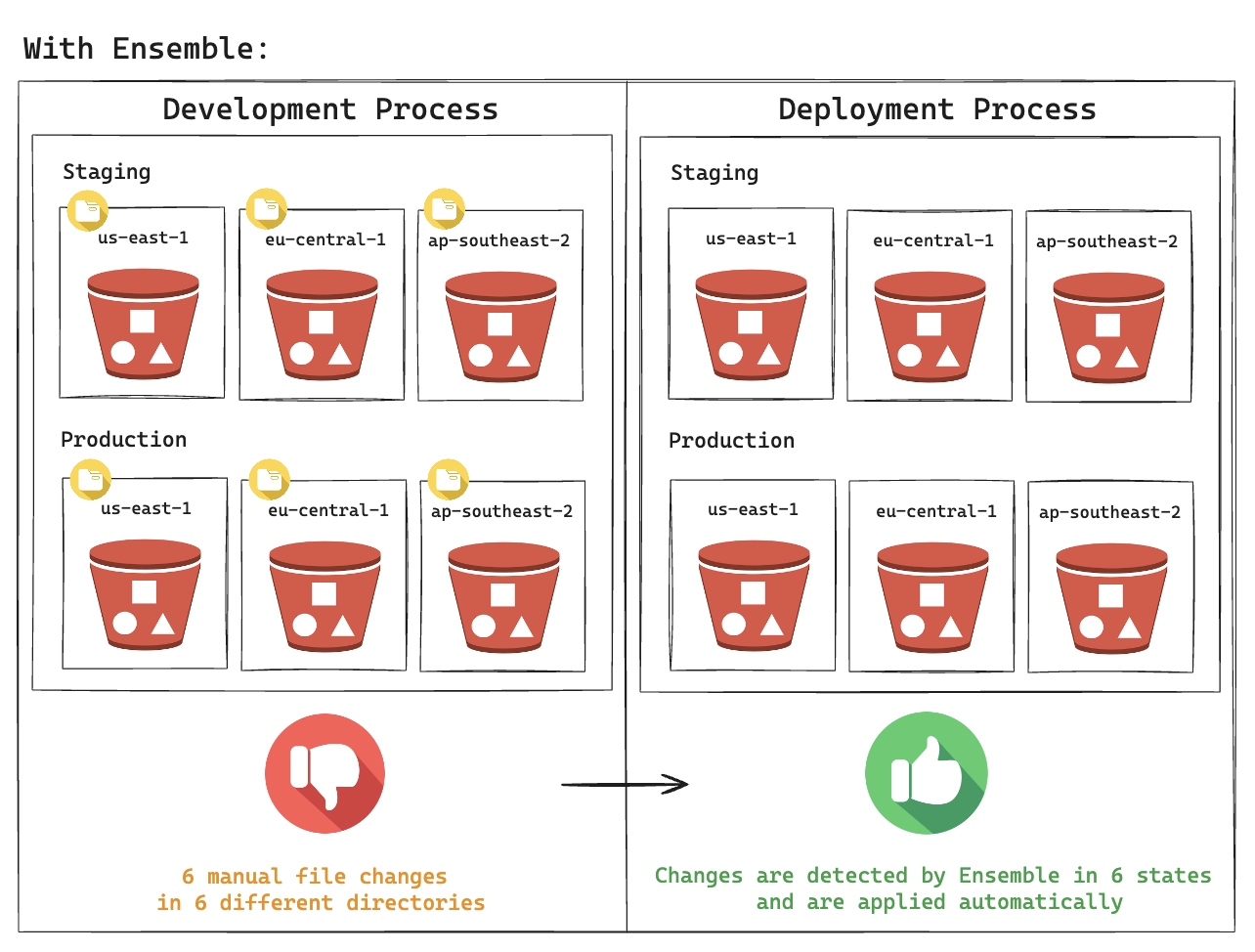
We understood that this way of managing our infrastructure is not scalable, and is blocking us from moving fast towards our plans of moving to a cell-based architecture. This architecture includes an isolated environment for each set of accounts with its own infrastructure resources, meaning our infrastructure should grow significantly soon.
When planning our new infrastructure development process, we had the following requirements:
- Keep Terraform states isolated to reduce potential risks and the deployment time of a change
- Have a centralized place for configuring common values for a resource
- Have the ability to override the common values in multiple levels (environment, region, and cell)
- Develop as little orchestration as possible
Possible Solutions
Terraform Workspaces and tfvars files
Terraform Workspaces allows the creation of separate states for a single configuration instead of requiring multiple directories. The configuration of a resource is defined once, and then it can be applied multiple times with different values using tfvars files.
The state file is created under the configured backend path within the env:/ directory which contains a directory for each workspace with its state file.
Selecting a workspace can be done by running the command terraform workspace select -or-create <workspace>. From this point on, all Terraform commands run within the selected workspace and with the provided tfvars files.
The example below demonstrates the usage of Terraform Workspaces for configuring and creating EKS clusters. In this example, EKS clusters can be of a different “type”, and can be deployed in a different environment, region, and cell. Each level (type, environment, region, and cell) could potentially have its common values, which would be defined as a tfvars file and would override the previous level values. For example, values of “general” type and production environment (general-prod.tfvars) would be overridden by the values of “general” type, production environment, and us-east-1 region (general-prod-use1.tfvars).
Terraform configuration for EKS clusters would look like this:
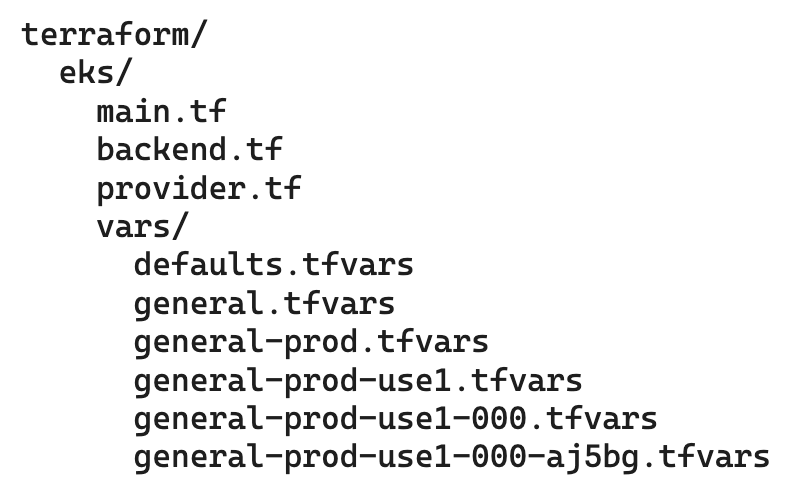
In this example, we have defaults.tfvars file which contains the common values and overrides tfvars file for each override level (type, environment, region, cell, and cluster). We would use these tfvars files to create an EKS cluster named “aj5bg” of type “general” within the production environment, the us-east-1 region, and the cell id “000”. The commands we should run to create the cluster would look like this:
cd terraform/eksterraform workspace select -or-create prod-use1-000-aj5bgterraform apply -var-file=vars/defaults.tfvars -var-file=vars/general.tfvars -var-file=vars/general-prod.tfvars -var-file=vars/general-prod-use1.tfvars -var-file=vars/general-prod-use1-000.tfvars -var-file=vars/general-prod-use1-000-aj5bg.tfvars
* The example above is just a demonstration, as there are many possible implementations of workspaces and directory structures.
* For application-related resources the directory structure is much more complex.
We can also use ${terraform.workspace} inside our Terraform modules and set the parameters of resources according to the name of the current workspace.
Using level-scoped values files allows us to have DRY code, with the ability to modify the value of a variable across all environments, regions, and cells in a single place. In addition, in the example above, creating a new EKS cluster doesn’t require any additional tfvars file unless the new cluster has its specific values (the cluster name can be taken from the workspace name as described above).
Terraform Workspaces can be combined with Terragrunt to generate the backend and providers dynamically and define the tfvars files to use and their override order according to the current workspace.
This solution suits all our requirements, except that it requires a complex orchestration of detecting file changes and planning or applying the relevant resources in the relevant workspaces. For example, changes in vars/general.tfvars should be applied to clusters of type “general” across all environments and regions. For this, we need to hold a cluster to type, environment, region, and cell mapping and use it to find which clusters need to be planned or applied.
It’s possible to integrate this orchestration logic into our in-house Terraform CI/CD tool, but we thought it would be better to find a solution that requires less orchestration development.
CDKTF
CDKTF (Cloud Development Kit for Terraform) is a tool for provisioning infrastructure with Terraform but using a familiar programming language instead of HashiCorp HCL.
When creating a CDKTF project we can choose a language and then CDKTF generates classes out of the configured Terraform providers and modules. Using these classes, we can define our infrastructure and then deploy it using the CDKTF CLI.
The CLI can be used for planning or applying the defined infrastructure (cdktf diff or cdktf apply) or for synthesizing the code into a JSON configuration that can be used by Terraform directly (cdktf synth).
A CDKTF project consists mainly of the following components:
Appclass – a set of infrastructure configurations.Stackclass – a set of infrastructure resources that share the same state (equivalent to Terraform working directory).Resourceclass – Terraform resource. These classes are generated automatically according to the configured providers.
The following file is the main file of our TypeScript CDKTF project for managing EKS clusters:
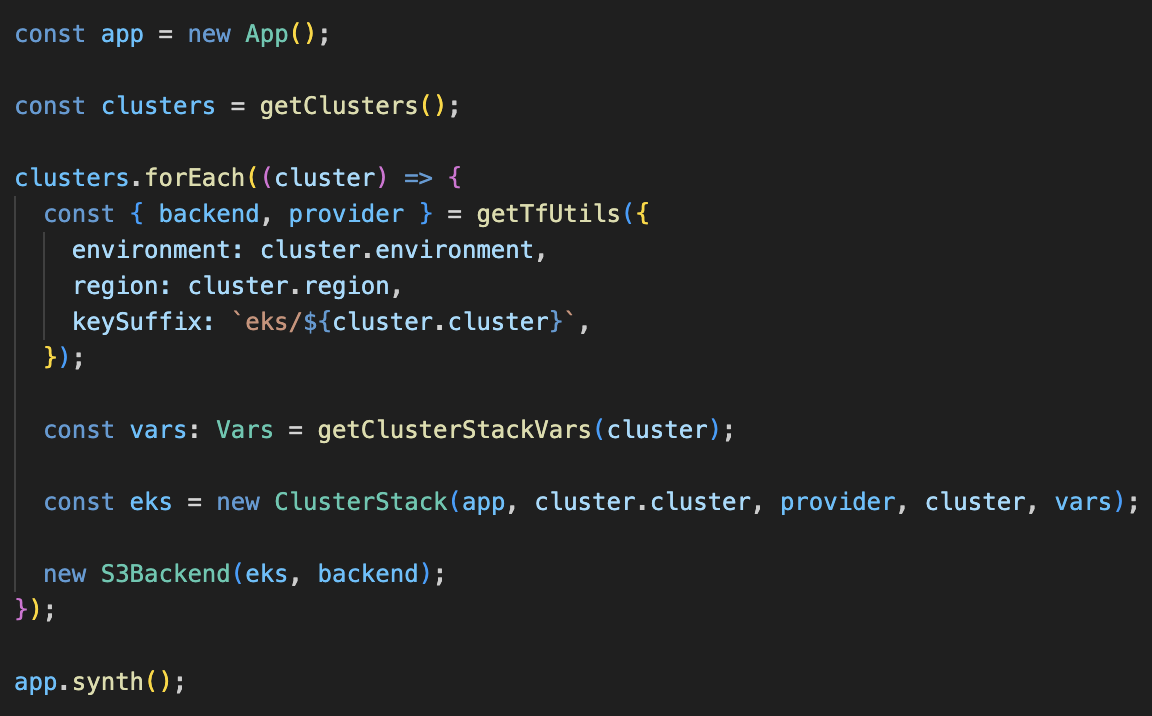
The main file reads the clusters configuration (type, environment, region, cell, and name) from a configuration file (getClusters) and for each cluster generates a backend and a provider (getTfUtils) according to its configuration, and a stack (ClusterStack). Each cluster has its own stack, meaning each cluster has its own state file.
The stack contains all the relevant resources (EKS cluster, Auto Scaling Groups, ArgoCD cluster registration, and more) according to the generated values of the cluster (getClusterStackVars). The values generation is a merge function that merges the configured values in all levels (type, environment, region, and cell) in the right order.

When running cdktf synth, the main file reads the clusters configuration file, and all the defined resources within the cluster stack are generated into a JSON configuration inside the cdktf.out directory in the root directory of the project.

All we need to do to plan or apply this cluster is to change the auto-discovery logic of Ensemble to detect changes in the cdktf.out directory and run Terraform commands inside of the parent directory of the changed file.
With this CDKTF abstraction, there is no need for any other orchestration. Running cdktf synth on Git pre-push Hook or using a CD pipeline would regenerate the clusters .tf.json files which then would be detected by Ensemble on PR and the changes would be planned or applied.
The main benefits of using CDKTF for our case:
- It’s much easier to manage complexity and logic with a programming language rather than with HCL (for example conditions, loops, merging complex objects)
- It allows us to change the value of a variable in a single place and automatically propagate it to all the relevant resources without developing any orchestration tool around it
- It allows us to dynamically generate backend and provider without any additional tool such as Terragrunt

Another main advantage of CDKTF is that on synth it also generates the manifest.json file that contains each stack and its dependencies.
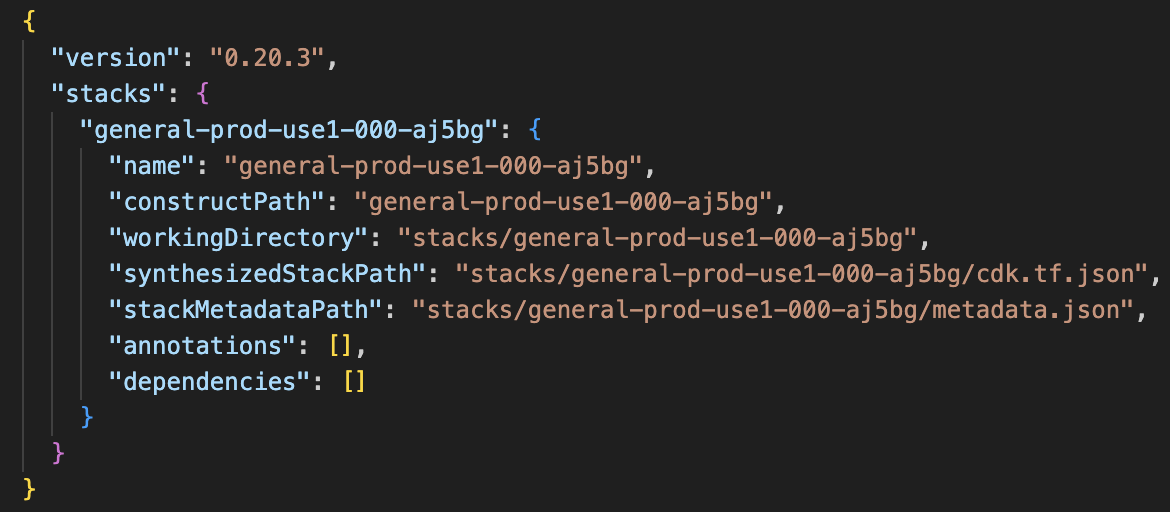
In the above example, each cluster is standalone and doesn’t depend on any other cluster, but there are cases when resources of different states are dependent on each other. For example, creating an SNS topic subscription requires an existing SNS topic and an existing SQS queue. With Terraform HCL, we can get one of the resources as data in a different state and use it, but it’s hard to impossible to map all the dependencies in order to plan or apply them in the right order as part of a CI/CD process. With CDKTF, we can leverage this manifest.json file to do so in our CI/CD tool.
Conclusion
While Terraform Workspaces is a great solution, and there are probably other good ones, we found CDKTF and its flexibility suits our current and future needs.
Our first CDKTF implementation is for managing EKS clusters, and we are currently working on an implementation for all our application-related resources.
We have also created a basic UI in Sphera, our internal developer platform, that displays all our existing clusters and allows us to create a new cluster. Submission of a new cluster adds the cluster to the clusters configuration file in the CDKTF repository, runs cdktf synth and opens a PR that triggers Ensemble due to a file addition in cdktf.out directory.
In addition, we have added the ability to see if a cluster differs from the region-level configuration (has cell-level or cluster-level overrides) which helps us be aware of differences and align values across clusters of the same type and within the same environment and region.



