
How We Shortened Development Feedback Loops From 30m to 30s
monday.com runs on 100k+ vCPUs; you cannot run that on a laptop. This physical reality created a 30-minute tax on every developer’s day – a substantial delay in our feedback loop.
Since a fast feedback loop is fundamental to pushing features, gaining market traction, caring about your customers, staying ahead of your competition, and, in the end, earning money.
In this post, I’ll introduce you to monday.com’s approach to this problem–one that suits the unique needs and workflows embedded directly into our core.
I’ll focus less on the technical details and more on the sociotechnical challenges you will face in big organizations.
monday.com’s scale
| Environment | Nodes | vCPUs | Memory | Usage context |
|---|---|---|---|---|
| Production | 4,900 | 90,000 | 292 TB | Global user base |
| Staging | 645 | 6,700 | 25 TB | Tests, automations, Monday Mirror (~200 users) |
| Ephemeral | 140 | 617 | 2.32 TB | Isolated (~50 Users) |
Compute requirements per environment
I assume monday.com’s system complexity and the development issues that arise when you use 100k+ vCPUs globally aren’t a surprise to you. You cannot run the whole of monday.com on your laptop, which is the root of the problem. There is simply no mobile device on the market that offers 40 CPUs and 140 GB+ of memory to run the system on a local Kubernetes cluster.
This is a digression, but who knows – maybe with further Moore’s law improvements, we will be able to in a few years.
Our Existing Approach
The industry-standard solution to this scale problem is leveraging the cloud. By tapping into public infrastructure, you gain access to near-infinite compute resources.
The typical pattern involves spinning up individual, isolated, and ephemeral environments per developer, allowing them to test changes in a realistic system.
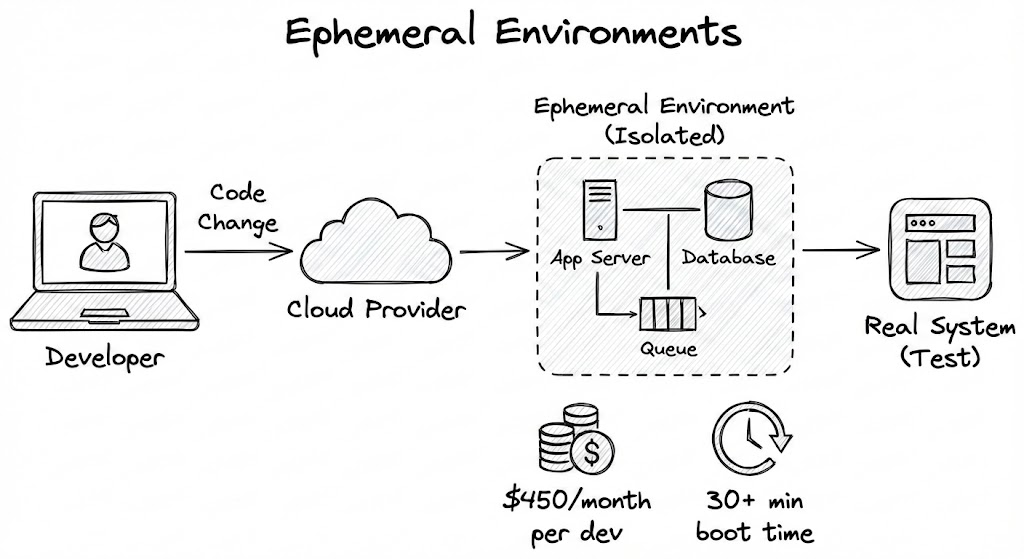
It might be enough for your use case, but we discovered substantial drawbacks and challenges:
Driving cost
To support just ~50 active users in ephemeral environments, we had to provision on average 140 dedicated nodes. This added a direct infrastructure cost of approximately $450/month per developer, purely to keep these isolated environments running.
This is on top of the staging environment resources we pay for, regardless, which also support a larger user base of ~200 users.
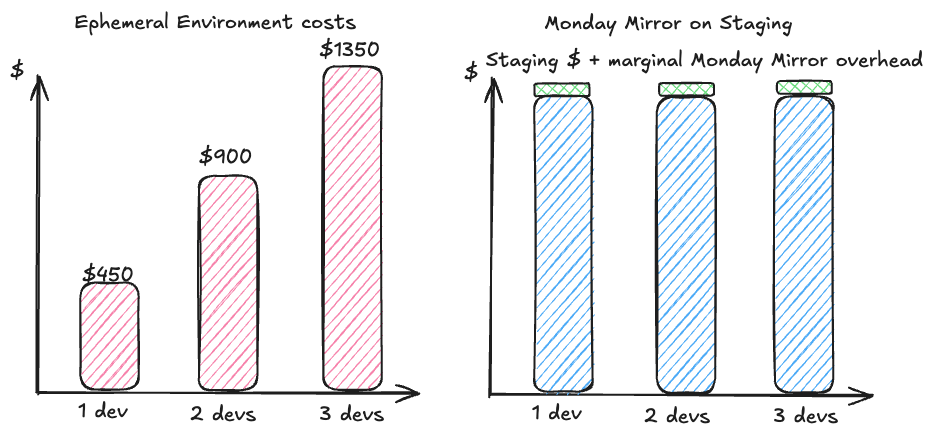
In summary, instead of adding a new cost that scales linearly with the number of developers, we can just tap into existing staging resources that we need anyway. In fact, the more developers use Monday Mirror with staging, the more efficient this tradeoff becomes.
Cold boot
When we talk about tight feedback loops, we want to eliminate all unnecessary time delays. I am not too old to remember the classic XKCD comic that showcases a problem analogous to a cold boot: long compile times. It demonstrates that, as an industry, we have simply learned to accept this as the status quo and live with it.

Source: https://xkcd.com/303/
Nowadays, in our development process, we wait for this flow to complete at least once a day, or multiple times a day, depending on the diversity of projects our engineers are working on.
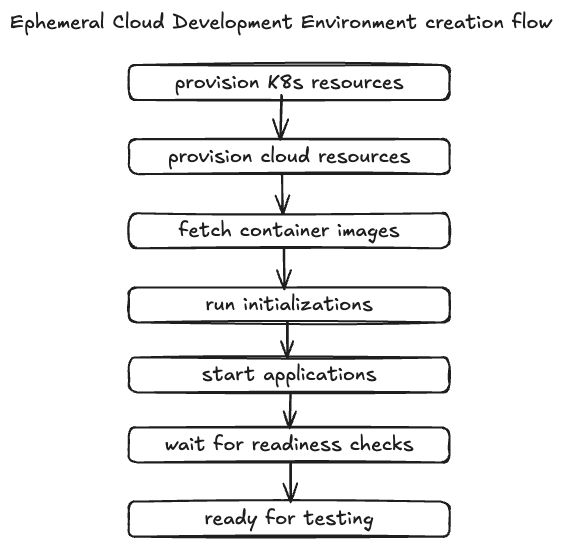
End-to-end, this flow might take even 30 minutes when spinning up the core of our system: the Monolith and its dependencies.
We identified this as the main friction point for both business and developers. Not only does it reduce agility, but the time investment is also substantial; with about 1,000 developers, you spend 500 hours daily just waiting for the ephemeral development environment! It’s equivalent to 3 months of full-time development work.
Satisfaction loss
Developers have neither the time nor the patience to wait this long to see their impact on the system as a whole. This drives satisfaction down, people get annoyed, features are delivered more slowly, and you lose the agility critical for keeping up with the market.
Summarizing the business costs
All of these factors – the hard and quantifiable resources, the wasted time, and the less quantifiable social problems have consequences measured in real money.
Doing some napkin math, it costs us ~$450/month per developer just for ephemeral infrastructure; when you add the wasted time and frustration, the total cost for monday.com easily exceeds hundreds of dollars per developer per month!
One can see that it is clearly not an optimal solution. So, how about we shift our perspective and instead inject the laptop into the cloud?
Monday Mirror – Our Solution!
![]()
Meet Monday Mirror, which is based on the Mirrord tool.
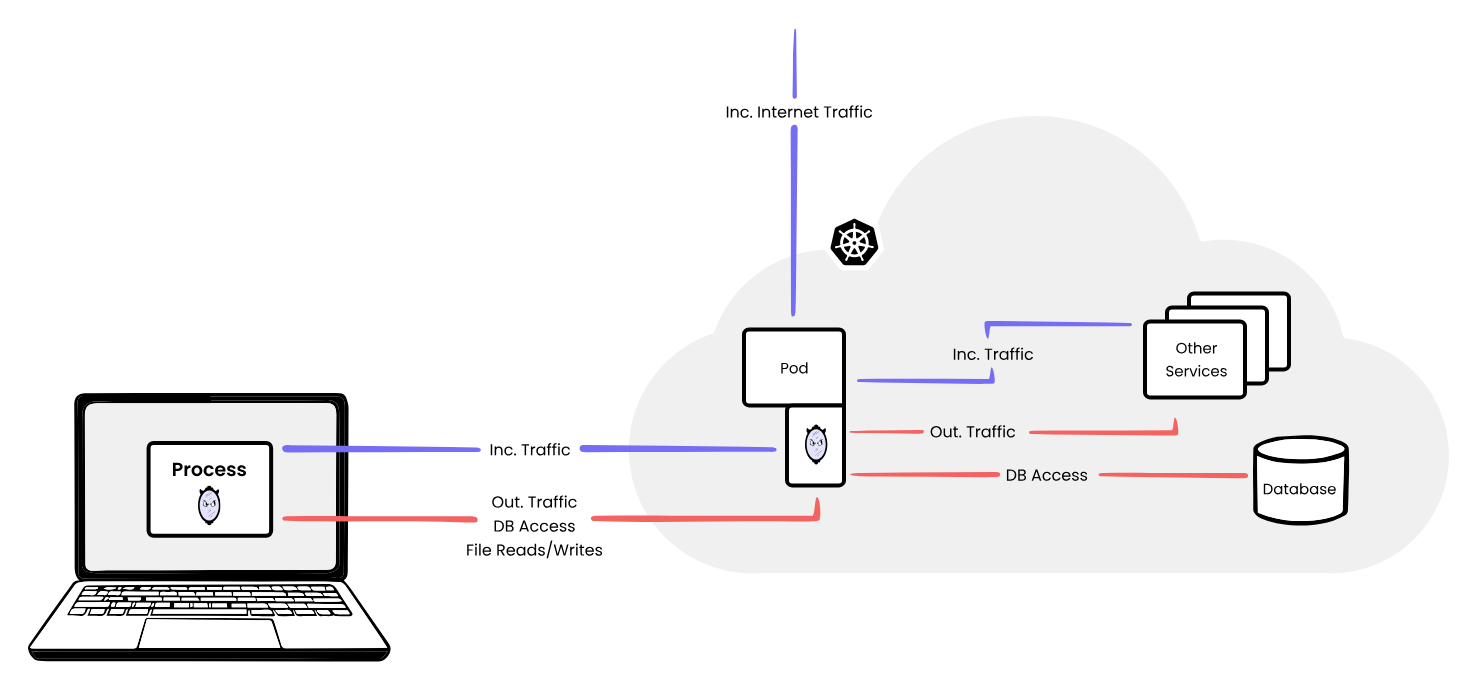 Source: https://metalbear.com/mirrord/docs/overview/introduction/
Source: https://metalbear.com/mirrord/docs/overview/introduction/
We didn’t choose this approach simply because the tech is interesting; we chose it because it systematically dismantles the barriers I mentioned earlier.
Decreasing costs. By sharing staging resources and intelligently hijacking traffic, we can literally reduce costs by $20k+ per month by simply cutting out the ephemeral environments.
Solving the cold boot. This was the most critical metric. Unlike the cloud-based full-environment approach, Monday Mirror, thanks to Mirrord, simply injects into the existing staging clusters with less than 30 seconds of overhead.
Improving developer satisfaction. We deeply care about our developers and want them to focus on driving business value, not fighting with tools. With Monday Mirror, we codified organizational processes and flows, as well as integrated directly into the developer’s toolkit.
Navigating Enterprise Security. We were looking for a solution that would streamline security rather than making it harder. Thanks to Mirrord’s syscall hijacking approach, we can transparently inject into a process’s I/O without root permissions, routing, VPNs, or other networking issues.
In summary, it suits our needs well. On top of that, because we own the Monday Mirror code, we can codify monday.com’s unique needs.
Building Monday Mirror was easy; getting 1,000 devs to trust it is hard
Building the tool was easy. Fitting it to monday.com flows, processes, variety of toolchains, and projects – and getting hundreds of engineers to trust it – is the hard part.

As monday.com prioritizes a bottom-up approach, we need to choose a strategy that reflects this.
Golden Path
A “Golden Path” isn’t about enforcing strict rules; it’s about making the right way the easiest way. We couldn’t afford hundreds of developers reinventing the wheel every time they spun up an environment.
We adopted an opinionated, “batteries-included” approach. If a developer stays on the Golden Path, they get Monday Mirror pre-configured, security best practices baked in, and instant platform support – for free.
We integrated Monday Mirror directly into our internal CLI and scaffolding tools. It wasn’t presented as an optional utility they had to download and configure; it became the default state of development. By removing the friction of choice, we reduced cognitive load. Developers didn’t have to “learn” the infrastructure; they just had to run the standard start command, and the system handled the complexity in the background.
Education
You cannot simply send an email and expect adoption. To drive a bottom-up rollout, we treated internal education as a product feature rather than a lecture.
We tackled this through three high-touch channels:
- Hackathons: We gamified the adoption. By dedicating specific days to “DevEx,” we created a safe space for experimentation, turning solitary configuration tasks into social, supported events where early adopters could shine.
- Open Hours: We replaced formal tickets with an open Zoom room. This high-bandwidth, low-friction support allowed us to debug live. Crucially, if three engineers stumbled on the same step, we knew it wasn’t user error—it was a UX flaw we needed to fix immediately.
- Pair Programming: For teams with complex legacy setups, we offered white-glove onboarding. Sitting down to code with our users didn’t just solve technical bottlenecks; it dismantled the “us vs. them” wall, building the trust required for a bottom-up rollout.
Internal champions
For your tool to succeed, it must solve real problems for real users. Find brave collaborators from different teams, learn about their use cases, and recruit them as your alpha users. Once it works for a team, move up the ladder and choose different ones until your tool is complete and actually used by developers.
An interesting side effect of this approach is that you create internal evangelists who will pitch the product and share tips and insights on the next pain points in the organization. You will be surprised by how effective gossip and spontaneous conversations are.
User experience
This one is personal to me; it was the first task I faced after joining monday.com. What stood out to me was the Ownership and Impact I had. Given simply the pitch of the problem, I had to research the pain points, gather requirements, propose a Decision Record, create PoCs, and scale them out internally.
Ultimately, the idea is to treat your developers as your customers and follow industry practices around developing products – track and triage errors, gather observability, bugfix proactively, create support funnels and be empathetic and helpful!
Results
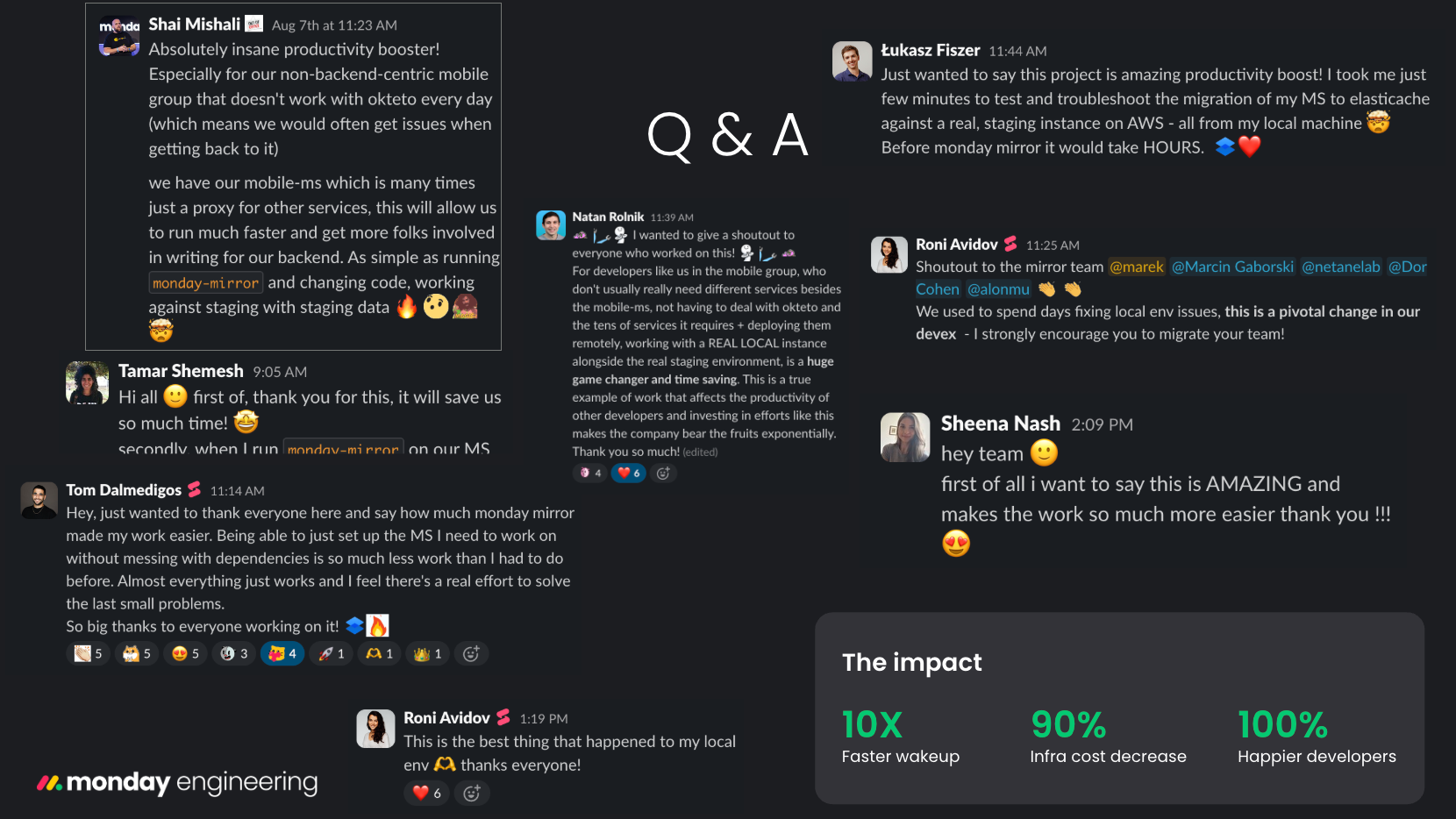
Moving from a technical PoC to a socio-technical tool changed the rhythm of our engineering organization:

Speed: We slashed feedback loops from 30m to 30s—a 10X faster wakeup that eliminates the context-switch gap.
Cost: By ditching ephemeral environments for Staging, we achieved a substantial reduction in infrastructure cost, saving ~$450/month per developer.
Productivity: 89% of engineers reported higher productivity, with one calling the shift a “pivotal change in our DevEx.”
Sentiment: The verdict is unanimous: 100% would recommend it, and 96% prefer it over the legacy workflow.
The Ultimate Lesson
The journey of building Monday Mirror taught us that at scale, technology is the easy part; process and people are the hard part.
“Don’t just build a tool – align it with your unique culture and focus on the ‘socio’ side.”
| ✓ | A technically perfect solution that no one uses is simply technical debt. |
| ✓ | If you fail to sell it internally, you haven’t solved the problem. |
| ✓ | True agility comes from culture, not just code. |
Credits
Thanks to Marek Pelka, David Gohberg, and Shahar Golan for creating the Monday Mirror and advocating for it.
Thanks to the Delivery Experience team – David Brenecki, Eyal Leibovich, Marek Pelka, Nave Levi and Piotr Duda for your hard work on Monday Mirror!
Written by Michał Szeląg. Feel free to say hi on LinkedIn!


