
When Infrastructure Becomes a Product
Two years ago, we realized that our feature flags setup was no longer scalable and was not far from becoming a real risk to platform stability as the system continued to grow. We didn’t have one tool, but several: some for the monolith, others for microservices, with no clear guidelines on which to use, when, or why. There was no happy path, just a fragmented set of solutions and a lot of undocumented knowledge.
At that point, it became clear we needed to act. The initial goal was straightforward: replace the existing tools with a more robust and resilient system.
In this post, I won’t focus on how we built a highly available, low-latency system (that’s probably worth a separate post). Instead, I’ll focus on the journey we didn’t fully anticipate: how we started with a relatively simple idea for an internal feature flags and configuration management tool with a dedicated UI, which ended up becoming a full internal product we later named Ignite 🔥. This tool is used today by over 600 developers across around 400 services, with ongoing evolution and product-level ownership.
At the time, I was a tech lead in the Foundations group and part of our Developer Experience team. I initially took ownership of the problem, starting with research and design, pushing the initiative forward, and kicking off the initial implementation. As the scope and impact became clearer, more developers from the team joined the effort, and what began as a focused project evolved into a broader team responsibility. After the first phase, we also involved a product and a designer in this effort.
This realization didn’t happen on day one; it gradually emerged as usage grew and users started treating Ignite less like a tool and more like a product.
More Than a Replacement Project
We started by defining requirements based on what we already had, and, more importantly, what we had learned from operating those tools in production.
We reached out to actual users – developers across monday.com – and interviewed them about how they use feature flags today, what they’re missing, and whether they follow any common release strategies. These conversations were extremely enlightening.
Developer experience wasn’t our primary goal at this stage; resiliency and performance were. But the interviews exposed how fragmented the release process really was. Some teams had well-defined strategies, others relied mostly on gut feeling. Even the basic question of when feature flags should be used at all didn’t have a consistent answer.
At that stage, most user needs were relatively straightforward; the main request was to add UI and visibility for our existing microservices feature flags and configuration tool (remember, we had different tools for monoliths and microservices).
Later, as our dev culture evolved with a stronger focus on quality, feature requests became more advanced: feature flags, dependencies, support for alpha groups, visibility into flag exposure by account, and more. The gap between initial requirements and eventual usage showed us we weren’t just replacing a tool – we were shaping how teams work, and in general showed us we are on the right track with this project.
We also evaluated off-the-shelf solutions and spent time testing a few. Build vs. Buy is always a hard decision with many factors, and what’s right at one point in time can shift as the organization grows and evolves. At that time, we decided to build internally. Key reasons why:
- Some tools were overqualified for what we needed back then, offering many features we didn’t require yet.
- We wanted to stay aligned with our internal developer portal, which already centralized day-to-day dev operations. The portal handled UI, authorization, and other aspects that would have required custom integration with external tools.
- We needed specific functionality we could control and customize, like default release rules and guidelines tailored to our standards.
- Cost scaling was a concern. As we grew rapidly in both headcount and system usage, many tools would scale in cost per seat or per usage, which didn’t align with our trajectory.
These factors led us to build in-house.
With that, we defined the initial scope for phase one and moved into technical design, with a strong focus on resiliency, scale, performance, and future extensibility.
Once the design was ready, we ran an internal roadshow with relevant foundation stakeholders, both technical and managerial. This stage took longer than expected: we had to align multiple groups, gather feedback, and iterate on the design. But once we got alignment and approval, it was go-time.
Adoption Is a Product Problem
A few months later, we had a working alpha: a TypeScript server-side SDK and a dedicated UI integrated into our internal developer platform, allowing dynamic control of feature flags. Configuration management joined shortly after.
To gain confidence, we started by dogfooding the system in our own team’s microservices. After that, we expanded to a small, hand-picked alpha group of services and teams.
Even though integrating Ignite was roughly a five-minute task (installing and initializing an npm package), we chose a hands-on adoption approach. We wanted users to feel supported, so we actively guided teams through onboarding, opened a dedicated Slack channel for support, and continuously gathered feedback.
Later, once it had already gained production mileage, we also added the Ignite SDK to our newly created microservices template, so users didn’t even need to integrate; they could just use it.
Some factors that significantly helped adoption:
- The tool provided immediate impact for the users (devex, audit, performance)
- Simple or pre-integrated setup via templates
- No forced migration of existing flags
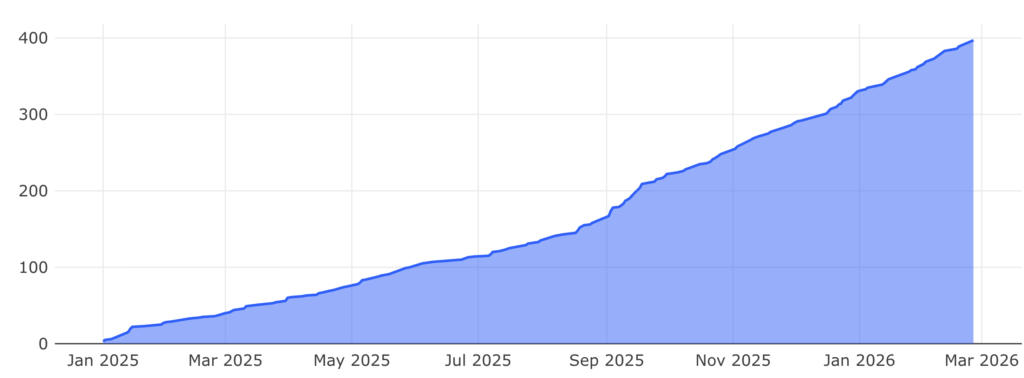
Ignite adopting services
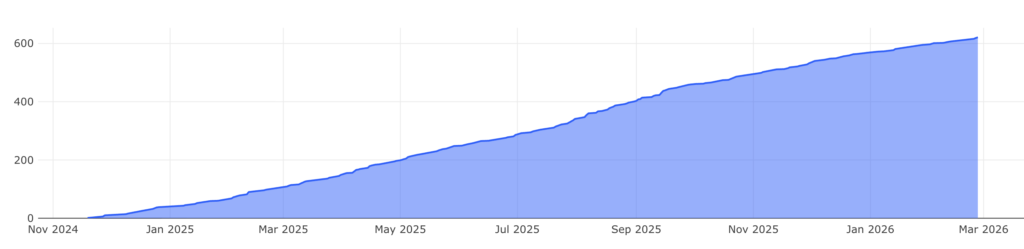
Distinct users using Ignite
The moment we started defining how teams ship
Around the same time, we experienced an increase in platform-related incidents. This wasn’t caused by our new system, but it drove a broader push toward stricter standards and more disciplined use of feature flags.
Some incidents were also directly related to the legacy tools, which further paved the path for adopting the new system.
As a result, we revisited our release “happy path”, the recommended, safest way to roll out most changes, and introduced a guided release wizard. The wizard walks developers through the release process: which environment or region to deploy to, rollout percentages, cooldown periods between steps, and peak hours to avoid.
This was a pivotal moment. We weren’t just providing a tool anymore. We were defining the release process itself.
We debated how opinionated to be: strict enough to reduce risk, but flexible enough not to block teams. The compromise was to allow opt-outs for specific, legitimate use cases, though we set the guided path as the default.
Beyond the wizard, we invested in education – making feature flags and release strategies part of onboarding for new joiners, covering best practices and how to reduce risk across the SDLC. At this point, the goal was no longer just to build a tool, but to actively shape how releases are done.
The Friction of Change
Change is hard. Developers want to move fast, and introducing a new tool that sits directly in their day-to-day workflow inevitably comes with friction.
Some of the main challenges we faced:
We chose not to be backward compatible
We made conscious decisions not to replicate all existing features. Some choices were functional; others were based on non-functional lessons learned.
One example, in the legacy system, two flags with the same rollout percentage (say 10%) were guaranteed to expose the feature to the same user population. In the new system, this is not guaranteed; each flag’s population can differ. Feature or bug? Opinions varied.
From our side, the new behaviour was the correct one for having a fair feature distribution, even though users were used to it and expected the same behaviour.
Limits were a feature, not a bug
We defined a clear happy path for releases, introduced usage limits (e.g., configuration object size), and removed certain capabilities such as runtime updates from application code. These decisions improved safety and predictability, but they also required teams to change habits.
This created friction when teams expected capabilities we’d intentionally removed. Most use cases were due to “bad habits” from the legacy system, but some were legitimate and forced us to reconsider. One example: direct targeting of 5,000+ accounts (meaning only those will get true evaluations). Previously, developers could write a script. Now it had to be done through the UI, which wasn’t built for this and was tedious for large-scale operations.
In the same example, there was also a limit on the number of direct accounts targeting 5k, while in the legacy system, it was unlimited (one cause for the bad performance it had)
Alignment is hard at scale
Keeping R&D aligned on new tools and standards in a hyper-growth organization is challenging. Often communications are done via Slack channels, maintained documentation, and include the tool in onboarding sessions, but this remains an ongoing effort and far from bulletproof. Slack messages are often ignored, are not relevant to new joiners, and require updates to documentation, and so on.
What We Learned
Decisions need a paper trail
We often found ourselves re-explaining why certain decisions were made. Even when discussions happened, the reasoning wasn’t always audited. Using ADRs (Architecture Decision Records) earlier would have saved time and confusion. Decisions can change, but the “why” should always be clear.
Don’t compromise the core objective
Our main objective was resiliency and performance. Developer experience was important, but never at the expense of the core goal. From day zero, we invested in observability and performance monitoring to continuously validate that we were meeting it.
Bring your heaviest users in early
While we involved many stakeholders early on, most were from infrastructure and foundation teams. Product teams, the heaviest users, joined later, which led to late feature requests and questions. Some were mitigated; others required explaining trade-offs. Earlier involvement would have created better alignment.
Build the guidelines into the flow
The user’s expectations should align with their user journey; documentation is good, but it’s not always used by users and often needs updating. When we introduced the guided release wizard, we basically removed the “release process guidelines” document we had, as well as any prior knowledge some developers had.
The Shift That Happened Gradually
What started as a technical cleanup quickly turned into a product with real users, expectations, and long-term ownership. The shift from project to product wasn’t a single decision – it emerged gradually through adoption, incidents, feedback, and responsibility.
Once a tool becomes critical to how teams ship, you’re no longer just building infrastructure; you’re owning a product, whether you planned to or not.


