How to replace your database while running full speed
This is the story of how we replaced our analytical database in my department while going full speed, with zero down-time & zero data-loss. and how you can do it too.
So imagine, you have the following requirement:

And now, let’s see now how that’s totally possible.
Working as a Tech-Lead in monday.com, in the BigBrain department- where we consume, store, analyze, display & play with lots of data, I was part of the efforts migrating our analytical database last year.
First, before you’re going to replace your current data storage solution, ask yourself a few questions:
- Why do I want to do this? is it performance issues? security? storage? cost? stability? reliability? something else? of course, you should answer those questions looking ahead to the future.
- What database solution will be good for me? Don’t take this step lightly, since it will probably dictate your (hopefully) next few years.
- How am I going to do it? A.K.A My migration plan — do I lift & shift or do I re-engineer? What are my steps?
- Who — You need to allocate the relevant people for the job: Developers, Data engineers, Data Scientists, Infra, IT, QA, Analysts, Finance, Legal.. Each one of them will probably be involved is some way or another with this migration. prepare them for it. You might want to consider a dedicated migration squad that can correlate the efforts and progress from each team.
- When (Time lines) — After you calculated the exact time lines for your chosen strategy, please add (at least) 50% to your carefully analyzed estimation.
— — — — —
So how it was done in monday.com? let me answer the above questions one by one —
Regarding the Why — our previous data-provider (I prefer not to name names), just couldn’t handle our hyper-growth, and in the last few months we experienced more and more:
- Production incidents — memory consumption issues
- Degraded performance — more load both on write & reads has influenced the overall performance.
- Queries failing— since db queries queue became full
- Increased cost — adding more and more machines to support our growth in data & BI tools added to our ongoing cost.
What we decided on, after examining & comparing a few alternatives was Snowflake. it’s a managed cloud solution which answered our demands:
- we don’t need to handle storage issues since the data resides in the cloud & managed by Snowflake.
- Since the storage layer & the compute layer are separate, we can add or reduce our compute warehouses on demand, and only pay for what we use. on most “traditional” databases, The peak performance required will dictate your allocated resources.
- Snowflake has modern database capabilities which we were missing with our previous provider (data governance, data insights, and more)
Now regarding the How – The steps I will outline should guide you no matter what is your source & destination data providers.
by the way, we decided to do a “simple” lift & shift, since we understood this is a major project as it already is, and it doesn’t need any more complications.
Before you start:
You need to clean

Are there any tables/data which you’re not using? what about your db related code?
most modern databases can give you insights regarding data usage and/or query history — from those you can understand which tables you’re using and the ones you’re not, where the latter is more relevant for us.
If you’re don’t use a table for more than *up to you to* — archive/delete it. You will save time, effort & cost both in this migration phase and also in your day-to-day work. remember — the fastest & cheapest data to transfer — is no data. the most bug-free code — is no code.
Prepare your new destination
Create the needed environments/schemas/tables/views/etc. in the destination database.
Since Snowflake has some differences in it’s SQL dialect compared to our previous data provider, we created an in-house tool which takes the DDL script for each table/view and transform them into Snowflake dialect (Snowflake also offers some SQL conversion scripts we used).
Sometimes you won’t have the same column types in both databases, decide on a type conversion method and stick to it.
Now, let’s talk about writes
That’s right. The next thing you will want to do, is to write your all of your data to your brand new shiny database. I will split this stage into 2 major parts:
- “The Old” — Existing data
- “The New” — Live/Streaming data
For existing data, you “simply need to copy&paste” the current data from one provider to another — there are several tools that can replicate your data. We decided to create an in-house tool for the job as well— since each existing tool will take you time & effort to integrate with, I created a simple tool that basically:
- Receives db information & schema/table name(s) (source & destination)
- Creates the appropriate table(s) in Snowflake (external table as well)
- Extracts the data from the source database into appropriate S3 buckets
- Load the data from S3 to the external table
- And from the external table copy the data into the final table
We even fine tuned our tool to replicate only by specific keys, if needed, since some tables where just too big to dump them all at once to S3 (degraded performance, remember?).
This tool was later used by different data practitioners in our group to load data from specific tables on demand (using airflow DAG).
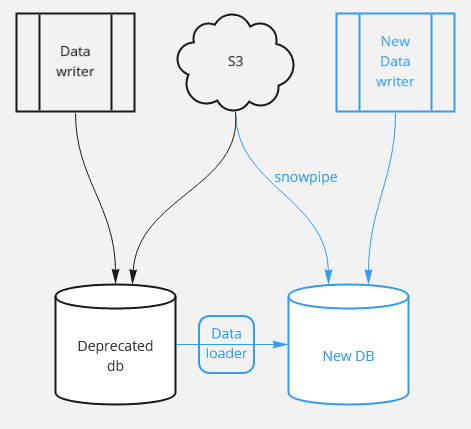
For live/streaming data the approach is different. First, you should map all the writes. Those can be from your application(s), your ETL jobs or any other task that inserts/updates data into your db.
- For Scheduled/ETL jobs — Duplicate each one of them. change the new jobs accordingly to match the new db connection/SQL dialect/etc. make your new job(files) completely independent on the original job(files), so when the time comes, you will just need to stop/delete the old ones and be done with that.
- Some databases offer tools for loading data— research it. For instance, one of our tables was populated from data which was streamed into S3. Snowflake has a tool for that: snowpipe.
- For application writes it gets a bit trickier —Now, as a rule of thumb, analytical databases, should not have single inserts/updates/deletes. this is more a characteristic of an operational* database, which we had as well, and was not part of the migration process (we’re still working with PostgreSQL). So if you have such writes to your database, that’s generally a bad practice. This is one of the places it wasn’t just a plain “lift&shift” but we decided to “amend some historical sins” and changed those writes to the operational db. if we needed that data in our analytical database as well, we used an open source solution named debezium to capture the changes in those tables and bulk load them every few minutes to our analytical tables (notice there’s a penalty in the “freshness” of the data we were willing to pay).
- If, for some reason, you still need to write directly from your application to your analytical tables and you need the data available immediately (bad design which is too hard to change at the moment, data-freshness needs, ..), use feature flags in your code that you can switch on&off during your migration process (e.g. WRITE_TO_OLD_DB, WRITE_TO_NEW_DB, WRITE_TO_BOTH) — more about feature flags, going forward.
*A simple guideline to distinguish between operational table and analytical one — if your business/application can’t run without it — it’s operational table. if your analysts can’t — it’s analytical
OK, so you’re done with the writes. or are you..? Validation time is
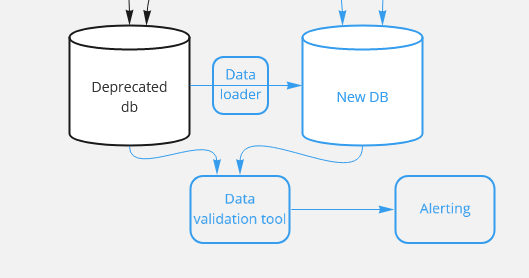
This is not an optional step. You can’t continue to the next step until you 100% sure your data is valid.
Run periodical jobs that compare & alert on any discrepancy between the databases. you should compare ALL tables & ALL views.
Some tables are huge, and comparing them row by row can take too much time— try to compare aggregations first to speed up the process (count, sum, etc.). But eventually, you should compare each table column by column, even if you random sample & compare only part of your data.
Some tables are populated only once a day — compare them once a day. some are being updated constantly — compare them more often, but take into account the possible lags between both databases.
This is also a good stage to check the performance of your new database, measure the times of fetching the same amount of data between the databases, if needed — add primary keys, partitions, etc.
This periodic validations step should be always up & running, and should be stopped only when the old database is switched off.
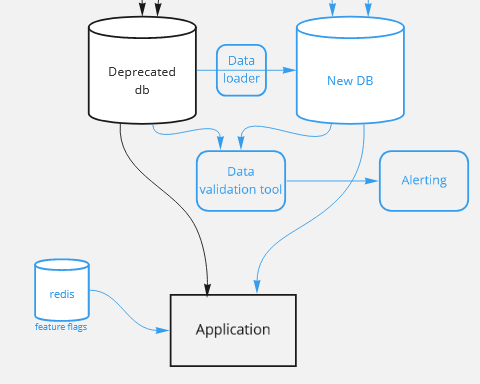
Almost there.. now you can start switching your reads
from the deprecated db, to the new one. for that we used feature flags per feature/table. we used redis db to store the current state of each feature flag and each application pod checked the needed feature flag before each read. this way, we could switch back & forth between the databases with ease (In case we needed to).
pseudo code:

This will add almost no latency to your code (especially if you’re using an additional cache layer with timer, that only refresh the state from redis every X minutes)
What about the queries from your BI tools (redash, looker, etc.)?
There are several ways to tackle this :
- Queries conversion tool that convert the queries, run them against the new database & compare results.
- Hackathon day(s) were all analysts/developers/migration squad joining forces on queries migration.
- combination of the above.
In addition, we logged each read from our old database, so we could track using our central logging for any such read and handle anything we missed. once we switched all reads to the new database, well..
Congratulations, you’re.. almost done
Don’t turn off your old database just yet.
Change the connections details for your deprecated database. Did something break? Did u get any alerts? unit-tests still pass? Is everything running smoothly?
It is much faster changing the connection details back in case of failure than switching on & off your database.
So is it over now?
Well, it’s one way to look on that. But the journey continues.. Now you should monitor & improve the cost & performance of your new database, growing it together as your product grows. good luck!
miscellaneous:
A few more tips worth to mention:
- Tutorials, docs, FAQ, Cheat Sheets
- Dedicated slack channel — where everyone who’s involved can ask, answer & share knowledge
- bi-weekly migration meetings — usually involving the migration squad (1 representative from each team ideally)
- Dedicated migration boards — we managed all of our migration using monday boards: