
Guarding the herd – managing database servers at scale
Over 400 million terabytes of data are created every day which sums up to 147 zettabytes over the whole year. If you don’t know how much zettabyte is – 1 zettabyte is 1 billion terabytes. The amount of data the world creates and consumes is growing at a crazy pace with estimations that 90% of the world’s data was generated in the last 2 years alone. Information is one of the most valuable assets that a company can possess and databases are a critical part of every company’s infrastructure. monday.com is no exception – we are a data-centric company.
The evolution of data layer
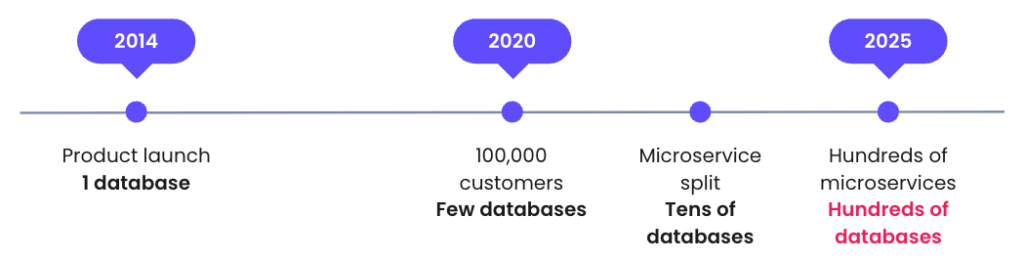
Let me tell you the story of monday.com. Our product launched in 2014 and it was a monolith application with a single database. We didn’t have a lot of data as we had only a few customers. The company grew very fast, and 6 years later, in 2020, we surpassed 100000 customers. As you can imagine, the volume of data also grew significantly, so we added replicas – read-only clones of the primary database – and separated reads and writes. With this addition we reached a dozen databases, a number that still can be managed even by a single DBA. Then, like many other tech companies, we decided to split into microservices as developing one monolith application started to become very hard with a growing number of developers, new features, and the complexity of the system. We extracted key parts of the system into microservices with their own, separate databases. This way, instead of a few databases, we started to manage tens of databases and this was no longer feasible for one person. At this point, the DBA team was established. There were a few people with database expertise and still everything was working fine.
Now let’s talk about today – today we have hundreds of microservices and still growing. As a consequence, we have no longer tens of databases. Now we have hundreds of them. Our team is already very big but with the exponential growth of database servers, it’s no longer feasible to just hire more people and still manage databases in an old way.
At some point, we changed the team name from the DBA (Database Administrators) team to the DBRE (Database Reliability Engineers) team. It actually reflects the shift in our approach to managing databases. We can try to summarize it in one sentence – treat your databases as cattle, not pets. DBRE is a different mindset. You simply cannot manage every single database server because there are too many of them. You need to manage a group of database servers at once. In case of stateless workloads, it’s much easier. The Kubernetes node has some malfunction – let’s just replace the node. But in this case we have databases that are stateful. We cannot just replace the server in case there is a failure because we have our data there. It makes it tricky to treat databases as cattle and it’s not an easy task.
A long way from DBA to DBRE
We agreed that a few principles must guide us in becoming a real DBRE team.
Standards
The herd consists of the animals of one species as they have the same needs. Our database herd has to be of the same kind. We cannot afford to configure every single database separately for different needs. It doesn’t mean that we will have databases of only one kind and we will have only 1 group of databases. We can have multiple groups. In monday.com we group the resources based on tiers.

Tier 1 are the most critical services that are crucial for the platform to work. Tier 3 are some peripheral services that won’t affect most of our customers if they are down. We have different standards for tier 1 and tier 3 databases. We can simplify some of the procedures for tier 3 databases, as even if the database is down for a few seconds, no one will probably notice it. For tier 1 databases, it’s unacceptable to have even the shortest downtime so our standards have to reflect that. Tier 3 databases have much lower traffic while tier 1 databases serve incomparable amounts of queries in a second. We will use different instance families for them, different storage types, and different numbers of replicas. For tier 3 databases, we can allow automatic minor version upgrades because even if something goes wrong, there is a lower chance that anyone will notice it. For tier 1 we do not allow it – we need to carefully test the upgrade and only then upgrade the database. Having those standards in place allows us to focus on the needs of specific database groups instead of reviewing every single database separately. If some standard needs to be changed for one tier 1 database, it probably also needs to be changed in the rest of the tier 1 services. The standards can be set for different aspects of database management – configuration, procedures, playbooks, monitoring and alerting.
Automations
If we have our standard configuration and procedures, we cannot apply them to each database manually. Every single action that we perform on a database should be automated. Even if we have a script to perform such a procedure automatically, we simply cannot connect to each database separately and run this script because we have hundreds of servers. We need to think bigger. What we need is a comprehensive toolkit that knows the context, the standards, and when and where it can execute certain procedures. DBAs need to learn software development. And what is more – we need to have standards also for this. We cannot write bash scripts that we keep on our laptops and execute them there. We need to stick to the standards of the software development process – write tests, have a proper CI process, reviews, approvals, CD, and gradual releases. We need everything that is considered as production readiness for software. There are no shortcuts here – our software has to be bulletproof. It will be running critical tasks on database servers. Can you think of a more critical incident than a data loss? We need to trust our code in 100%.
Self-service
If we already have our automations for all procedures on databases, why should it be us to execute them? It’s a development team that owns their microservice – why don’t we let them own their database? Our job here is to use our knowledge and skillset to actually decide what we need to automate, how to do it in a safe way and then expose this procedure to database owners. When we create a new microservice, the developer should mark a checkbox if they need a database or not, and in case they need it, it should be created automatically. When a developer wants to create a backup on demand, they should be able to do it by just clicking a button – without involving the DBRE team. When they need a new replica, increase the storage, increase the machine size, etc, they should be able to do it on their own. Of course there are some actions that maybe shouldn’t be so common and should require at least DBA approval. Maybe some critical actions shouldn’t be exposed to development teams at all. If it’s a tier 1 database, maybe we should have approvals for every possible action. Everything depends on the organization’s requirements and specific context. The idea here is that we should offload the most common and safe operations and shift them left.
Observability
Again, we cannot do it manually. We cannot connect to a specific database and run “show processlist”. We need proper monitoring for every aspect of a database. The critical part here is alerting. And again, the alerts shouldn’t necessarily come to us. For example, storage size alerts can come directly to the development team, and in case it’s low, they can increase it on their own. Some of the alerts shouldn’t notify anyone but they should just trigger a proper remediation. Of course, in case of some critical events like “server down”, it still should come directly to the DBRE team.
So… what did we actually do?
Let me introduce you to project Shepherd. If the databases are our herd, the Shepherd is the guard which takes care of them.
Our first and foremost motivation to start the project was scale. We had plenty of repetitive, manual tasks that we had to perform on all of the databases and the number of them is growing constantly. Another problem that we wanted to solve was delivery consistency. We didn’t have any standards defined and the procedures were executed by different team members on different database servers. This fact led to human errors, misconfiguration, and discrepancies. Next problem – no single source of truth. One may say – just use Terraform or Crossplane or some other IaC tool. Well, it’s not that easy. We used Terraform for our RDS instances. The problem is that the database configuration is not just RDS – there are other things such as database user configuration, permission configuration, application secrets, tooling running on a database, or connection pooler configuration, like PgBouncer or ProxySQL. All of this makes a source of truth for a database more complex than just keeping it in the Terraform module. Let’s take a specific scenario as an example – resizing a database server. Let’s say we want to increase machine size from large to extra large. It’s not just about changing the Terraform parameter called “instance_family”. The first step would be to drain the connections to the database. Once there are no connections, we will change the machine size. After it’s back up, we don’t want to just throw 100% of the traffic into it. We want to release it gradually – use our connection pooler to route 1% of queries to it. If everything is fine, increase the traffic to 5%. And so on until 100%. It’s more than just changing the parameter in Terraform – it’s the whole procedure and our single source of truth must reflect that.
All of this made us think about the requirements for the new system. We need it to be able to perform complex procedures that we can be decomposed into small tasks. We want those small tasks to be reusable. For example, a task to restart a server will be probably reused in many complex workflows. We want a way to test the complex workflows and find issues before they happen in production. As I said before, the key is the trust. We are talking about databases here – one mistake and the consequences may be terrible. We need a way to define the infrastructure in an imperative way. We need to have control over what exactly is happening in which order. For example, we cannot add a database to the connection pooler configuration until it’s fully ready with all other configurations. We want the system to be able to handle long-lasting processes that take days or even weeks. We have some huge databases in our infrastructure where executing a schema migration might take really long. We need a way to put a human in a loop. For some critical procedures, we want to have a way to pause the workflow, allow a DBA to check the status, approve it or not, and only then continue with the workflow. Another requirement is to easily integrate it with other systems. We have our internal developers portal called sphera and we want databases to be part of it. We want to give developers a friendly UI to monitor their databases and perform actions on them. And last but not least – a single source of truth. We need to have one place where we keep 100% of database configuration.
We decided that what we need is a workflow engine. We want to have a platform where we will be able to run our complex workflows without taking care of scheduling, retries or human in the loop. There are a lot of different workflow engines in the market but we chose Temporal. It’s an open-source workflow engine that is getting more and more popular. We picked Temporal because it offers much more than our requirements. It provides great visibility, easy local development, support for many languages, and easy testing.
Picking Temporal already fulfilled most of our requirements, but there is also one more – a single source of truth. The workflow engine doesn’t solve it – we need to have a way to pass proper input parameters to the workflows that we will have. We are a DBRE team, and we know databases well, so we thought – why not create a database to keep the configuration of all our infrastructure components? We decided that we would have Shepherd’s database where we would keep the desired configuration, actual configuration, and change log. Our idea was to modify the desired configuration, watch for differences between actual and desired configuration and if there is a diff – run a workflow called “sync” that will apply the desired configuration.
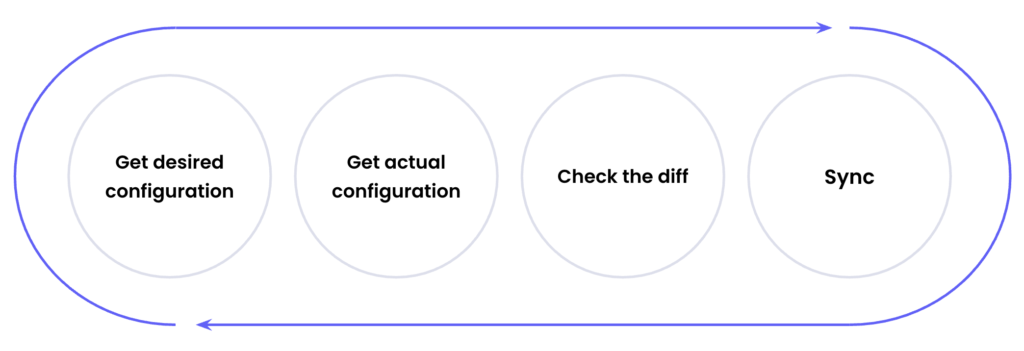
You may already know this concept from ArgoCD – we have the desired and live manifests and ArgoCD takes care of applying the desired configuration every time it changes. We want to use the same concept for our databases. It will also give us great visibility over drifts. We will see which databases are out of sync and if they need some manual intervention to remediate. Having a change log will allow us to quickly roll back to the previous configuration if something is not working well.
Now, the part of integrating with other systems. I’ve already mentioned sphera – our internal developers portal. We want to use it as a UI for our single source of truth. Everyone will be able to go to sphera, see the desired and actual configuration, see if we don’t have a drift, change the desired configuration, and monitor databases. It will be our self-service for everything related to database management.
It’s that easy… Well, not really
In a perfect world, that would be it – we have standards, we have automation, we give self-service, we have monitoring and alerting. But we all know that the world is not perfect. We won’t be able to automate every single action in the near future. Preparing such workflows can take a significant amount of time for development and proper, thorough testing before it’s released to work with production databases. And even when it’s released – we all know that there are chances that it will fail the first time we need to use it because of discrepancies between test/staging/production environments. The incidents will still happen and we won’t predict everything – we won’t be ready for every possible failure in our databases. That’s why we still need a backdoor. We still need a way to go to a specific database and do manual things. We need a way to change parameters in AWS. We need a way to manually restart a server. What I’m trying to say is that Shepherd is not only a workflow engine. It will still provide us with tools to do things in an old-fashioned way. We will have a code that restarts a database. It will be used in workflows, but we will still use the same code to implement, e.g., a CLI for our team to be able to restart a specific database with 1 command. Another example – we will open connections to databases in workflows to execute some SQLs there. We will use the same code to implement a CLI command which opens a connection to a database in seconds in case we need to do manual tweaks. So what is Shepherd after all? It’s a monorepo with all database-management-related code that will be used to prepare tools – from fully automated workflows through scripts that can be triggered manually to simple operations like connecting to the database to run SQL.
Conclusion
We have been working on Shepherd for quite some time already. We have our Temporal, and we have workflows running in production. The work is still in progress, and we are currently developing more workflows that will cover the most critical flows of database management.
Shepherd is going to be the heart of our team – it will allow us to keep everything moving forward fast, at scale, in a reliable way. The brain is the knowledge, experience, and expertise of all our team members. In the end, it’s on us to design and implement the solutions and to know whether to click or not to click the button to perform an action.


