
From API Chaos to Collaborative Graph – making API great again
As your company scales, so does the number of services and the number of domains that need to communicate with each other. Whether you consume or produce API endpoints, scale issues will follow.
When you need to consume a new internal API endpoint, some of these questions probably pop to mind:
“How do I access this API with proper authorization? What are the limits? What’s the output schema? What’s the versioning strategy? Can we optimize by removing some of the fields I don’t need for my use case?”
Some might be documented better, but even good open API documentation can’t answer all of these questions.
In the end, it’s the dev’s responsibility to ensure each endpoint meets the right standards that fit their domain and document it properly.
But what if you have many domains in your org? What if some of the endpoints you need to create have to be reused in subsets for both external and internal purposes?
Soon enough, you’ll reach a state of API chaos, as using new APIs stops being enjoyable and instead becomes a mess of documentation and different standards.
And, of course, producing these endpoints is no walk in the park either, with a lot of common boilerplate that is often not shared properly between services.
To understand what leads to this state of chaos, let’s look at the lifecycle of a single endpoint.
Why Decentralization Fails at Scale
The internal producer experience
You are a new developer (Hey Winnie) in your organization, and you’ve been assigned the task of creating the new board endpoint, which is exciting! You create your shiny new
microservices and start implementing the logic.
As you start working, you notice there is a lot more to it than just implementing the logic (here comes the boilerplate):
- First, you need to ensure stability by managing your limits.
- Second, you know things change, so you can’t commit; you need to take care of version control.
- Third, you want people to use it, so you ensure the right documentation is in place.
- Fourth, you want the best dev experience, so you need to create a package to export the endpoint types.
- Finally, you need to establish the right observability, so you’ll be the first to know about any trouble.
All of the above also need to be regularly updated as the service gets bigger.
Now, imagine you own more than one service, and the overhead keeps increasing… (Chaos!)
And at some point, you’ve been asked to release it externally with a smaller set of features, only to now be duplicating all of this…
Oh boy, think about using this API now…

The internal consumer experience
Like Mr. Pooh (aka Winnie from above), the organization usually has tens or hundreds of developers, and, surprise, surprise, as the organization grows, so does the number of services.
As a developer, finding the right endpoint and its policy is usually harder than actually using it, because different domains have different needs and standards you must apply – one team uses camelCase, another snake_case; one versions via the URL, another via headers.
Moreover, at times, you need to understand the internals to join different domains that do not naturally speak to each other. You need to become the glue – sometimes trying to glue water to wood.
And alas, all of the above need to be maintained, upgraded, and replaced, causing maintenance chaos. This leads to maintenance chaos, as the knowledge required to maintain your service increases with the number of APIs you use.
Luckily, you are within the organization, so you can find the right people to consult. At least you are not an external developer trying to use some of these APIs…
The external consumer experience
Everything the internal developer needs, the external developer needs as well. Maintaining the right versioning, limits, response, and error standards, while keeping a close eye on the changelog for potential breaking changes, is crucial for a seamless experience.
So, we have a scalability problem on all fronts. Let’s see what we can do to fix it.
The Centralized API Engine
Now, as promised, we’ll try to solve all of the above, while making the API fun again. We will achieve this by removing the boilerplate, implementing governance in a centralized layer, and automating all other processes.
Introducing Federated GraphQL
GraphQL is a simple query language over HTTP endpoints. It allows transforming all your APIs into a single endpoint Graph API that, instead of speaking in CRUD endpoints, speaks in entities.
Federation is the GraphQL spec that defines how to use GraphQL from multiple services. It enables you to distribute your graph across different services, creating distinct subgraphs, which a central Gateway then automatically stitches into a supergraph. This enables your API to scale horizontally while maintaining a single, unified interface for the client.
So now this chaos:
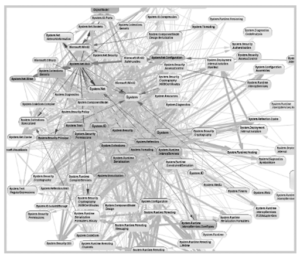
…is replaced with more structure, as one component manages the dependencies and makes sequences of calls:
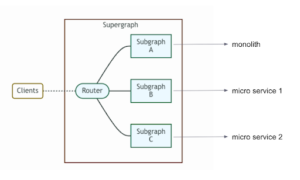
In the GraphQL architecture, all data is transmitted via the body of a POST request, and a centralized server controls access to data.
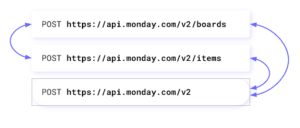
In the following example, you can see me retrieving data from a board and its workspace.
I don’t have to know who resolves the board endpoint or where the workspace originates; all I need to do is specify the entities I want and the fields I want from them.
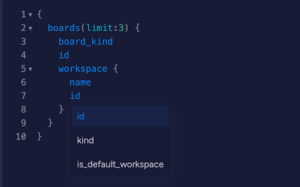 Wait, did I just choose what fields I need? Yeah! It’s dynamic!
Wait, did I just choose what fields I need? Yeah! It’s dynamic!
In GraphQL, each entity defines what it is capable of providing, and you simply need to choose. GraphQL is built on a supergraph that defines everything you can get from it.
So what’s in it for consumers?
We mentioned a single endpoint? That means a single governance layer! Now we can enforce different standards, such as naming conventions, error handling, versioning, and limits, all out of the box. No more knowing the internals, or which API is defined where. We have a single place that defines all possible types and auto-generates them based on the data you need.
And for producers?
When creating our APIs, we can now focus solely on the important stuff: writing the logic. Since the API is now part of a single supergraph, it comes with all the versioning, standards, release cycles, documentation, and so on, out of the box.
Additionally, since the API contract is now dynamic and consumers can select the set of fields they need, we eliminate complaints about performance optimization for specific field combinations. Each consumer takes only what it needs, eliminating the need to maintain API spaghetti 🍝
Going back to the boards–workspaces example: as the owner of the board entity, you don’t need to know about workspaces. When the workspace team wants to define this relationship, GraphQL Federation allows them to extend the board entity, enabling queries for workspaces by board ID – without the board team needing to be aware of it. Each team simply extends the shared entity, with no need to learn or depend on another domain. This approach keeps each domain fully owning its own surface area – and nothing else – which is exactly what GraphQL Federation enables 🚀.
Lastly, we discussed avoiding duplication of logic for both internal and external use. With our implementation, we can tag a field – for example, as “Internal” or “Public.” This allows us to control its exposure, preventing external access to internal fields – and sometimes entire entities – while maintaining a single definition for public fields. As a result, external users get the same performance experience we rely on internally in our own product.

Making it lean
We mentioned several concepts that are now being taken care of out of the box, but it’s certainly not without cost.
Everything here will need to be implemented (but only once, rather than repeatedly).
To address all of the above, we needed to create additional mechanisms on top of the GraphQL Federation engine.
The most important ones are:
- CI / CD – How we publish new API schemas.
- The API wrappers – What capabilities we want developers to get straight away.
- Centralized router – The central component that all requests pass through.
Let’s start with CI/CD:
For our centralized router to understand the flow and determine which field corresponds to which service, we need to maintain a mapping of these relationships.
GraphQL Federation achieves this by performing query planning for each request to determine where to go and when to go there. But we still need to hold this information somewhere.
Therefore, on each PR merge, we run logic that takes the Schema the MS generates and stores it in a centralized place. That way (and by following GraphQL Federation guidelines), we know what each service provides and when to route to it.
Additionally, to ensure all the developers follow the same standards, we built a CI action that reviews each PR and verifies that it adheres to the general guidelines.
For instance, with versioning, we ensure in the CI that users won’t encounter a breaking change by mistake, since new changes must be specified in a future version rather than included in a stable one.
Finally, as part of the deployment process, we can automate some of the boilerplate tasks, such as auto-documentation creation.
Let’s continue with our API-wrappers.
Like versioning, other basics, such as limits, are just one word away.
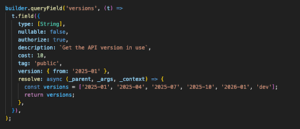
This is an example of how a field might be defined.
In the example, apart from the regular things like the type, we can see some of the wrappers we added:
- Authorize – takes care of entity-specific authorization logic
- Cost – allows the service to define field-specific limits
- Tag – defines the visibility of the field
- Version – allows you to define the API version for which the new field will be available.
Taking cost as an example, in the previous world, the developer needed to create a full limits service for the API; now it comes with merely a definition!
Depending on your needs, you can add any custom functionality you want developers to have, removing the extra overhead for all.
Finally, let’s talk about the central Router component. Because all API calls go through it, we can perform actions that benefit all services – such as collecting logs and traces for request tracking, emitting metrics for automatic dashboards, enforcing rate limits defined by subgraphs, and more.
From Boilerplate to Velocity: Standardize Once, Scale Forever
We developed our solution with the goal of making the API both fun and easy to use and understand. While we did it with GraphQL, other approaches are possible to straighten out the chaos.
Now, I want to challenge you. Do you enjoy creating new functionality? Or do you spend too much time on boilerplates, orchestration, and maintenance?
If it’s the latter, whether for API or anything else in your system, maybe trying to organize the chaos could be your next step.



