
Development environments in the cloud
How we at monday.com are running development environments with more than 30 microservices without burning our laptops
Intro
At monday.com we’re transforming the way people work by building a simple and intuitive WorkOS to connect teams around the world to their workplace processes while improving collaboration and communication along the way.
We have experienced hyper-growth in the last couple of years, increasing our customer base 3x on a yearly basis as well as doubling our engineering team each year.
This scale required us to make changes in our infrastructure, our deployment and release process. Changes were also required in the development environment used by our engineering team every day to adapt to the high pace of development and microservices architecture.
In production we’re running our workloads on EKS – AWS’s managed solution for Kubernetes (you can read about our migration to k8s here), using multiple types of databases.
We have a full Continuous Delivery process with numerous changes being released to production every day across multiple services by different software engineers.
Developers have end-to-end responsibility over the features they are working on: from development, through testing, to deployment and monitoring. New features are released at a blazing fast pace. Therefore, our development environment must be as good as it can be and it should be flexible to be able to adapt to new changes quickly.
Development environment issues, needs and solutions
Our development environment has a lot of moving parts in it – we have the platform’s monolith (written in Ruby), around 30 microservices (written in Node.js) each with its own set of DBs. There is also Ambassador – our HTTP gateway, and webpack (there’s more, but you get the picture).
When I first started at monday.com in June 2020, the development environment was in the process of becoming dockerized. The monolith and each of the microservice had its own docker-compose.yml defining the stack. Developers were required to create a docker network to enable services to interact with one another, as well as deploy a localstack to mimic AWS services in development (SNS, SQS and others).
Spinning up the environment from scratch was challenging, especially for new employees, as it required many manual installations. It could sometimes take a couple of days to have an environment up and running, which made developers frustrated and the onboarding experience hard (we have an internal new employees onboarding goal – to make meaningful production change during their first week, and the development environment should support this goal and not make it harder to accomplish).
Also, each docker composition deployment was resource-heavy, putting a significant load on our laptops and slowing them down.
At some point, it became almost impossible to run more than a couple of microservices concurrently.
Another issue was that some microservices depended on others, requiring developers to manually run docker compositions in a specific order to make things work.
This reduces productivity, becomes hard to maintain and keep up-to-date as new microservices are added.
We also experienced issues with file synchronization, which we solved by using a Docker Edge version supporting Mutagen (see here), which provided reasonably fast synchronization. This, however, bound us to a specific Docker version, which resulted in errors and strange behaviors whenever developers accidentally upgraded to an unsupported version.
All the above, made us realize that we need a different solution for our development environment.
This new solution needed to be easy to set up in a replicable way, be as similar as possible to our production environment in terms of structure and technologies, have a fast inner-loop workflow, and last but not least, not kill our laptops 🙂
It was also important to maintain a development experience that was as close as possible to what you get with a local environment. For example, hot reloading and debugging should work seamlessly.
After some research we found Okteto, which seemed to fit our needs and address our pain points: it allowed one-click deployment of git repositories from UI or CLI, had developers access a k8s namespace in a shared developer cluster (similar to our production environment which is running in k8s) and supported the ability to work on one or more components with changes being instantaneously synced – no committing, building or pushing needed. Also, Okteto’s configuration files at the time were pretty similar to docker-compose.yml which we already used so it made the implementation time shorter for us.
After a demo by the Okteto team, we decided to start a POC featuring our monolith and one of our microservices.
We wanted to see how easy it is to set up an already existing codebase in Okteto, how/if all our developer tools work (IDE, debugging, hot-reload, etc), how fast the synchronization of files was, and the general development experience.
We created a document defining all our goals for the POC, and one of its main parts was to make sure we can run two services in all possible combinations – one in Okteto and the other locally, vice-versa, both in Okteto, and both locally.
The most important thing was for us to give it to some developers to test and provide feedback as soon as possible to understand the value.
As you can understand from this post – the POC was successful and Okteto was chosen as our solution for dev environments.
How we work using Okteto
The first thing a developer should do is install the Okteto CLI and login to the Okteto UI using GitHub – this is done once on the first-ever usage.
Once the developer is logged in, a k8s namespace is created for him in Okteto’s cluster (dedicated to monday.com and not shared by other clients).
Each namespace is personal for the developer and will contain all deployments.
Namespaces can be shared with other developers which is extremely cool for helping each other with debugging or even pair-programming.
As mentioned we have a monolith written in ruby which is needed to run our platform.
Most of the developers will need to deploy it even if they work on other microservices because most of the flows still need it in some way or another.
We deploy using the okteto pipeline deploy method, which deploys from git on a specific branch, identifies the type of deployment based on the okteto files the repo contains and can be customized to use other okteto commands which is exactly what we do in the monolith. See the okteto-pipeline.yml below:

Here we deploy some microservices which are needed for the monolith to work (monday-aws-localstack, authentication, authorization and column_values), we build the webpack Docker image, install Ambassador and eventually deploy the monolith itself using the okteto stack deploy command.
Stack deployment is described in okteto-stack.yml which is very similar to docker-compose.yml (which is supported by Okteto but we haven’t tested it yet…)
Here is how our stack manifest looks like (minimized, just to get the idea):

You can see all the dapulse-* services we deploy, as well as all the different DBs and services.
Each service is actually a pod in the cluster and can be accessed by other pods using its name and port (for example http://dapulse-rails:3000)
Volumes can also be defined for services so that data will not be lost when redeploying/destroying the stack.
It’s also important to remember that behind the scenes it’s k8s, so kubectl can be used like in real production environments.
Docker image builds happen in the cluster, sharing the docker cache between deployments which helps accomplish an amazing deployment time of around 5 minutes for the entire stack described above.
Once the pipeline is deployed there’s basically a working environment running in Okteto’s cluster, and it looks like this in the UI:

But we said we want to develop, right? So now comes the other cool part.
Development mode starts by running okteto up command on one of the yml files described in the pipeline devs section (not a must to define there, but good for visibility).
Let’s say we want to start working on the rails pod, so we will run the following command okteto up -f okteto.rails.yml
This will create a developer pod, and swap the one running in the cluster with it.
A bidirectional sync process will start between the pod and the local filesystem and port-forwarding will be enabled to allow accessing through localhost or using a debugger.
This is how the manifest for rails development looks like in our case:

As you can see we use it for the sync as well as port-forward to all the DBs and other services.
Most of the time developers deploy the environment once using the pipeline and then work with the development mode. They switch branches, debug, and do whatever is needed while the sync process is running seamlessly behind the scenes.
Only when something is changed on the infra-level, for example, a new service is added, or some env vars related to deployment have changed there’s an actual need to redeploy the pipeline.
For ease of use, we’ve also added multiple aliases to our dotfiles repository (which you can read about here) so that there’s no need to remember/type all the most-used Okteto commands.

A basic developer flow when starting the day can be as simple as running ok-start which will open a couple of iTerm tabs with all the needed monolith stuff:
For our microservices the flow is pretty much the same – they’re also deployed using pipelines (even though most of them don’t have any complex flows there yet).
They have the same stack manifest to describe the services and okteto manifests to describe the development mode.
This is just the tip of the iceberg and you can imagine there are a lot more functionalities and use-cases to Okteto we don’t yet use (or need) so I encourage you to check out their website and docs.
Infrastructure and communication
Our cluster is running on Okteto’s cloud infrastructure, and we have an admin view in the Okteto UI in which we can manage users and namespaces and see the status of the nodes in the cluster. The cluster scales down when there’s no active development (weekends for example) and scales up when needed.
Upgrades to the cluster are done by the Okteto team, as well as updates to the CLI.
They’re fully planned with us in advance and changes are notified once applied.
We have a shared slack channel between our R&D and Okteto’s team, where we raise questions, issues, feedback, and feature requests – which we have a lot of each 😉
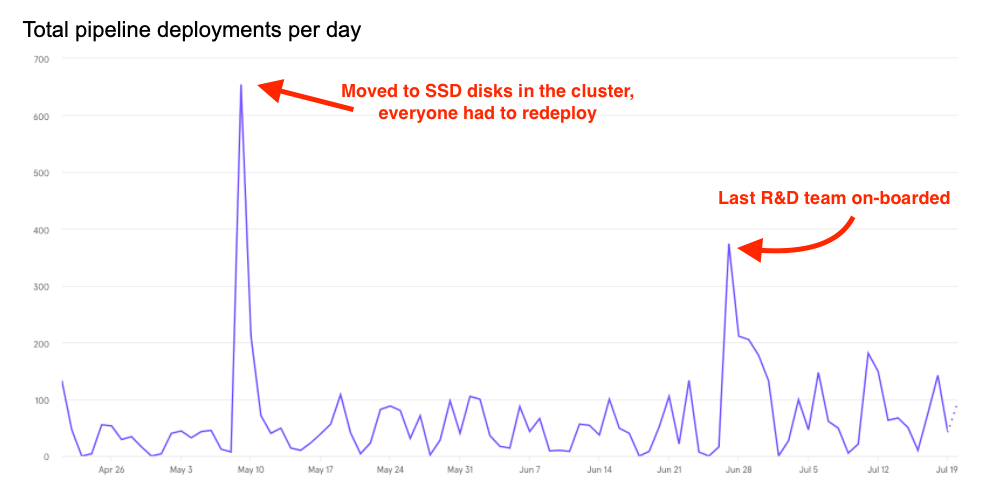
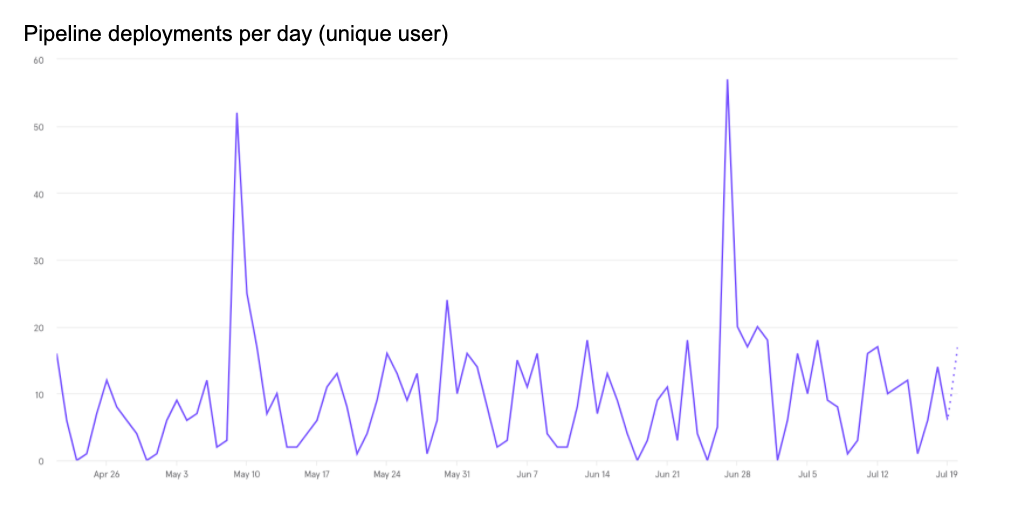
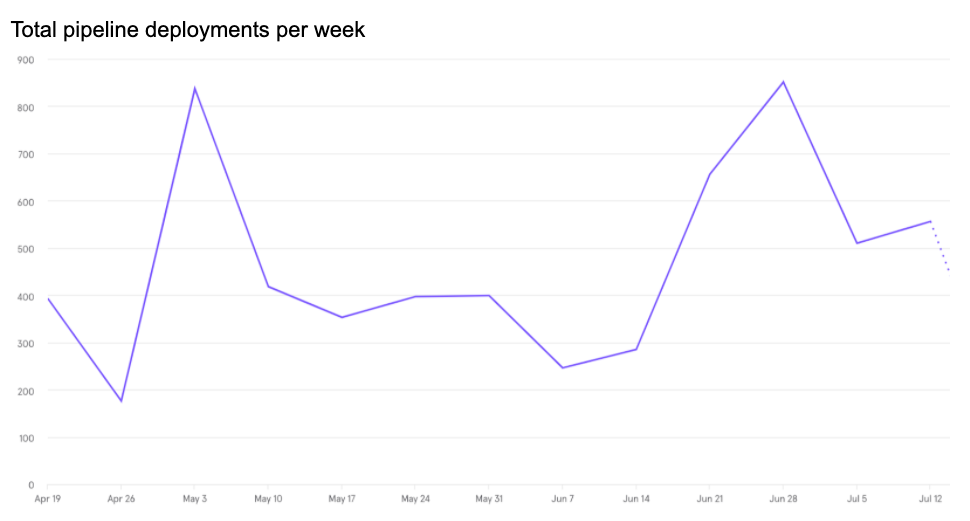
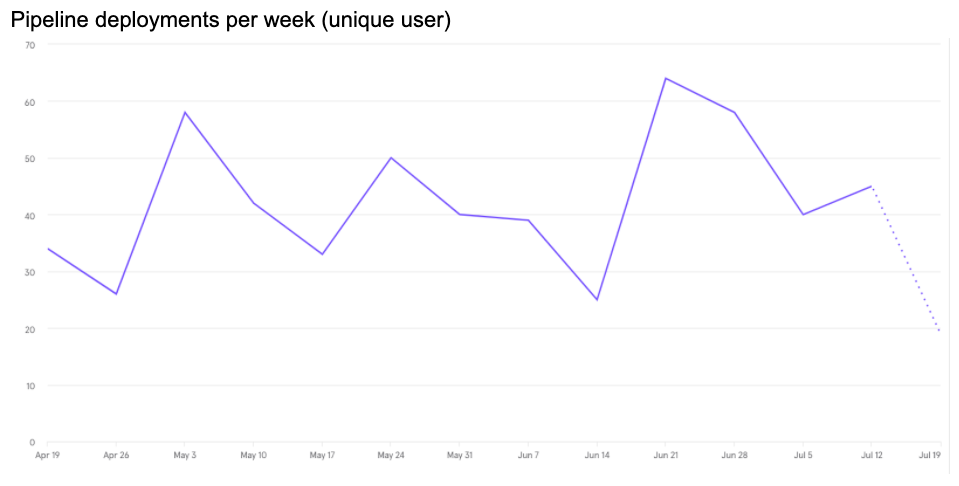
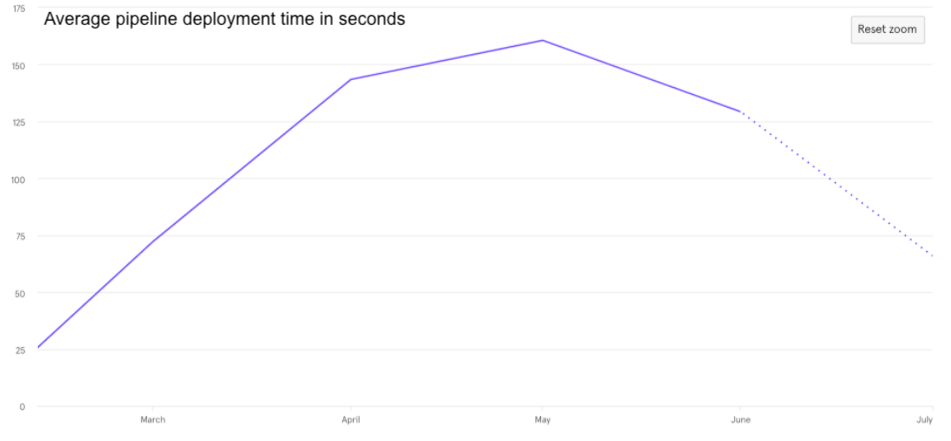
Some data
- 43 GitHub repositories are configured with Okteto
- 50 nodes (approximately) on the cluster at max load
- 103 developers have namespaces on Okteto cluster (almost the entire R&D)
- 85
okteto upsessions per day (unique developers running development-mode on average) - 95
okteto upsessions per week (unique developers running development-mode on average)
Some lessons we learned while looking for a solution for development environments
Developer experience is a major issue these days but it is extremely important and I know that all the things written below may sound a bit cliche or you’ll think to yourself “well, of course” but I still think it has value to people encountering this post and going in similar directions.
- Think of what you need in a solution, before you start looking for one
- Define what is a success in a POC before you start
- Involve as many people as possible as early as possible to get feedback – we at monday.com love getting and receiving feedback, and it really helps in driving you towards the solution or understanding early on if it’s not at all the direction you want.
- Try to be an expert in the product you’re trying to integrate – you’ll be the one mostly supporting others in your team once it becomes your selected solution
- Documentation is a MUST during the process and not at the end – it is easier to document what you do even if you have to update it during the work than to start writing it once everything is done and things seem clear to you but won’t be for others
- Share the knowledge as much as possible with many people as possible
- Help to understand the solution instead of just solving it for others
Benefits gained and feedback received
The productivity increase is huge – developers almost don’t need any extra time handling environment setup and can work on what really matters which is the product itself.
The onboarding process is a lot quicker for new developers – the development environment is up and running almost instantly, and can start working right away, helping achieve one of the main goals of our onboarding which is to deploy a real feature to production on your first week at monday.com.
Attached below is a screenshot of a survey we took a few months after onboarding the entire R&D onto the platform, as well as some feedback to understand the impact.

The future
As the scale of monday.com continues to grow, and the R&D team expands, more new services are created, existing ones are developed and new use-cases arise.
We need to make sure to support all those processes while keeping our environment simple and working efficiently and accustomed to our needs while staying as similar to production as possible.
Some of our thoughts for the near future include:
- Preview environments – when a developer creates a PR, a preview environment will be generated and can be shared with anyone not only on R&D to review before actually merging. This can help get feedback faster, and before deployment to staging which sometimes can take some time. The environment will be destroyed once the PR is merged/closed.
- Pair-programming – investigate the usage of okteto share option to allow pair-programming across multiple services making the integration happen locally making sure everything is working as expected before going on to staging.
- State toggles – use okteto’s abilities for shared volumes to allow a fast switch of the environment state (for example between a free account to an enterprise one)
Conclusion
Having a good development environment can be hard, but once you get it right the impact is huge. That’s why we aim at always improving deployment times, making sure sync is working and stable, and investing in our documentation and knowledge sharing so that everyone in monday.com’s R&D team can work and make a great product.
Want to join us?
Did you find this blog post interesting? Have you done it before or want to do it in the future? Take a look here or here and you might be the one writing the next blog post 🙂


