
Chaos Engineering Practices to Increase Confidence and Reliability
Usually, we attempt to keep our staging environment as stable as possible. But sometimes, you can benefit from inserting some chaos into it – to validate your assumptions about the health of your service, to learn about its dependencies, and to check your guardrails. In this post, you will learn how we at monday.com are using Chaos Engineering practices to achieve the same.
While our staging and production environments run on the same infrastructure stack, standard testing cycles often follow the “happy path”. Network jitters, pod evictions, and latency spikes can happen in any environment, but they don’t always happen exactly when we are running our test suites.
Relying on random failures to test resilience is not a strategy. We needed a way to execute managed chaos: deliberately triggering specific failure modes to verify that our applications handle them correctly.
Core Principles of Chaos Engineering
Before diving into the tools, it is important to define what we actually mean by “Chaos Engineering.” It isn’t about breaking things randomly for the sake of it. It is a disciplined approach to identifying failures before they become outages.
At its core, Chaos Engineering is about controlled experimentation. It follows a scientific method:
- Define a “steady state”: What does normal behavior look like? E.g., “Create Item requests return 200 OK within 200ms”.
- Formulate a hypothesis: What do we think will happen if we inject a fault? E.g., “If the database is slow, the application should return a cached response, not crash”.
- Inject the fault: We introduce the managed chaos – latency, packet loss, or resource exhaustion.
- Verify the result: Did the system behave as expected? If not, we have found a weakness to fix. If it did, we gained trust.
By applying these principles, we shift resilience testing “left”. Instead of discovering that our retry logic causes a retry storm during a production incident on Friday night, we discover it on a Tuesday morning in a controlled environment. The goal is to build confidence in the system’s capability to withstand turbulent conditions.
Chaos-Mesh
To execute these principles effectively, we needed a tool that fit our engineering culture. We didn’t want manual scripts; we wanted reproducibility. After some research, we chose Chaos Mesh because it integrates natively with Kubernetes, allowing us to define “Chaos”-as-code.
We create YAML configuration files that describe exactly what failure we want to inject. This allows us to version control our experiments and review them just like application code.
Let’s focus on 3 main scenarios that will show you the strengths of Chaos Engineering practices in general, and chaos-mesh specifically:
1. Network partitioning – internal dependencies
In a microservices architecture, your service is only as reliable as the services it calls. We use NetworkChaos to simulate a “Partition” where traffic to specific internal dependencies is completely cut off.
The goal is to verify that, if a dependent service becomes unreachable, the calling service handles it gracefully. Does it fall back to a default value? Does it return a clean error? Or does it hang indefinitely and consume threads? This helps us validate our internal timeouts and circuit breakers.
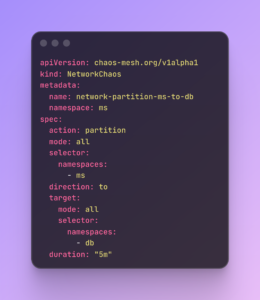
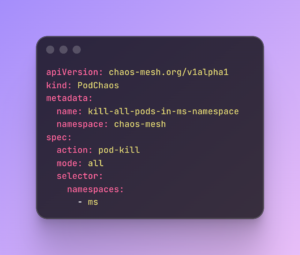
2. Pod killing – service resilience
Pods are ephemeral; they die, get evicted, or restart during upgrades. We use PodChaos to force specific pods to die instantly.
The goal is to validate the application lifecycle. When a pod is killed, does the service recover automatically? Do we have enough replicas configured to handle the load while the new pod spins up? This is critical for testing our readinessProbes and livenessProbes to ensure traffic isn’t routed to a pod that isn’t ready to serve it.
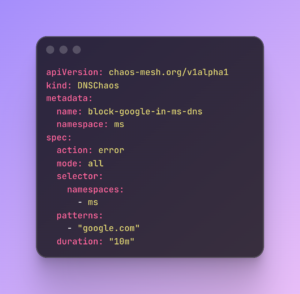
3. DNS Chaos – external dependencies
Our platform relies on various third-party APIs and external services. We use DNSChaos to simulate DNS resolution failures for specific external domains.
The goal is to see what happens when the “outside world” is unreachable. Simulating DNS failures helps us prove that our application remains stable even when external integrations are experiencing an outage.
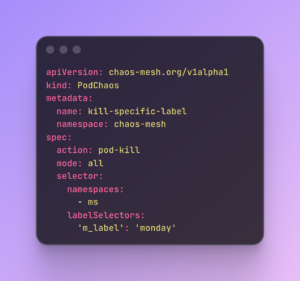
Controlling the Blast Radius
Crucially, since we run these experiments in a shared staging environment, we need strict control. We utilize the selector capabilities in Chaos Mesh to define the exact “blast radius.”
We can target specific namespaces, labels, or even specific pod versions. Here is an example of how we target specific pods (using labels) to prevent disrupting the entire cluster:
When Assumptions Failed
The value of this approach became clear when we tested one of our service’s internal timeouts. We assumed that if one of its internal dependencies failed, our circuit breaker would activate immediately.
However, when we used Chaos Mesh to simulate a network partition, we found the opposite. Instead of failing gracefully, the service hung for 30 seconds, stacking up threads until the pod crashed. The “resilient” config we had on paper was useless in practice. We fixed the timeout config that same day – preventing what would have been a major production incident.
Embracing Failure to Ensure Success
Our use of Chaos Engineering is about control.
If you are considering adopting these practices:
- Start with Staging: Use your pre-production environment as a proving ground.
- Start Small: Verify a simple assumption, like how your service handles network lag to the DB.
- Control the Scope: Use selectors to ensure your experiments are targeted and managed.
While Staging is our proving ground, our ultimate goal is Chaos in Production.
It sounds counterintuitive, but the most resilient organizations in the world (Amazon, Netflix) don’t stop at pre-production.
Staging can never perfectly replicate the “voodoo” of real-world traffic patterns and user behavior. By eventually moving these controlled experiments into production, we will move beyond testing our code and begin testing our entire ecosystem: our monitoring, our on-call rotations, and our automated self-healing.
Whichever Chaos platform you choose, the main goal is changing the paradigm: from assuming your system is resilient to proving it.


