
Creating Contractual Service Communication
In a microservices architecture, there is a silent killer: the implicit contract. Service A sends a message, and just hopes Service B understands it. At monday.com, with billions of daily requests, ‘hope’ isn’t a scalable strategy.
Some of these interactions are synchronous, some are asynchronous. Yet there is a fundamental missing feature. Since time immemorial, these flows have ‘stringly typed contracts’: you hope the producer and consumer agree, but there is no single source of truth that says what an event should look like, whether a change is safe, or who owns that definition. This leads to incidents, a horrible developer experience, and broken validations.
This post explains how we changed that by introducing explicit, versioned JSON Schemas, wiring them into our toolchain, and treating service-to-service communication as contractual.
The Communication Landscape Inside monday.com
This can be divided into two main categories:
- Synchronous communication primarily uses HTTP, with payloads in JSON, via either TypeScript, Ruby, or Go services.
- A large and growing asynchronous layer uses tools such as SQS, Kafka, Sidekiq, and Temporal to process both JSON and Protobuf events.
We wanted to prioritize this asynchronous communication because it provides better resilience, the ability to fan out events to multiple consumers, and improved control over back-pressure and retry behaviour.
What Was Missing: Contracts
We had no canonical way of answering the question: “What does service X actually emit?” To know, we could read the producer code, inspect the consumer’s parsing logic, or investigate data by hand. None of those told us what was supposed to happen; they only told us what happened recently.
There was also no way for a consumer to be notified of a schema change. If a producer decided to rename a field, change a type, or start emitting a new value, nothing in the system highlighted this before an incident occurred. In practice, consumers either over-defensively parsed everything as “string or null or anything” and prayed, or they failed in odd edge cases when a new state appeared.
On the DevEx side, every service had to roll its own JSON handling: manual parsing, manual validation, manual defaulting. There was no generic solution that ensured we had a schema; here is a generated type, here is a validator, use this, and you get consistency for free.
Choosing a Starting Point: Reporter Service
The Reporter Service sits inside the monolith and is responsible for maintaining the event history of the products we offer: activity logs, automations, and other internal event consumers. It receives a very wide variety of events and, in turn, pushes data out to multiple downstream systems. That makes it noisy, central, and high impact – the perfect place to start enforcing contracts.
The goal was clear:
- Define explicit JSON schemas for the events it was emitting
- Iterate over those schemas until they matched real production traffic
- Make those schemas easy to consume in TypeScript and Go
- Wire schema changes into CI so that breaking changes were caught before they reached production
- Hand ownership of each schema to a clear owning team, instead of leaving them in a no-man’s land
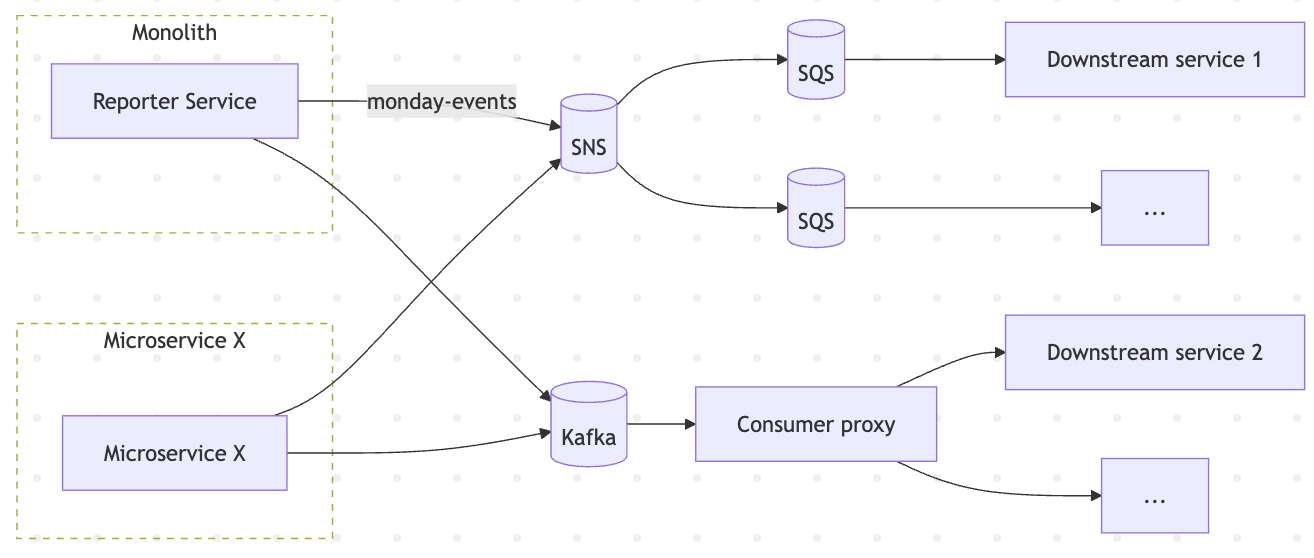
JSON Schema as The Contract
We already use Protobuf for some schemas, and we decided to go with JSON Schema here. JSON Schema gave us a formal way to describe the structure, types, and constraints of JSON documents: which properties existed, which were required, which were nullable, what types and formats they used, and how nested structures were shaped. It also supported composition and conditional validation, which mattered for richer events that we process. Being language-agnostic meant we could use it with Ruby, TypeScript, Go, and any other language that had a compatible validator, while using language-specific types from a single source of truth.
Our initial pass for each event type was to infer a candidate schema from existing payloads. LLMs were a force multiplier here, able to analyse large swaths of our codebase and create an initial foundational model of each event (there were 90+ in total). Once we had that baseline, we wired in a validator and ran it against real traffic. For every one of the roughly 100 million daily events flowing through the service, we collected pass-fail metrics and captured sampled failure logs so we could debug without drowning in data.
For each missing component, an iteration process then began: asking an LLM to fix the issue, reviewing the changes, and updating the validator. Common reasons included optional fields that sometimes went missing, new event subtypes we had not yet modelled, and subtle type differences that had crept in over time. We repeated the loop until each schema reached a clean 100% validation rate (see below).
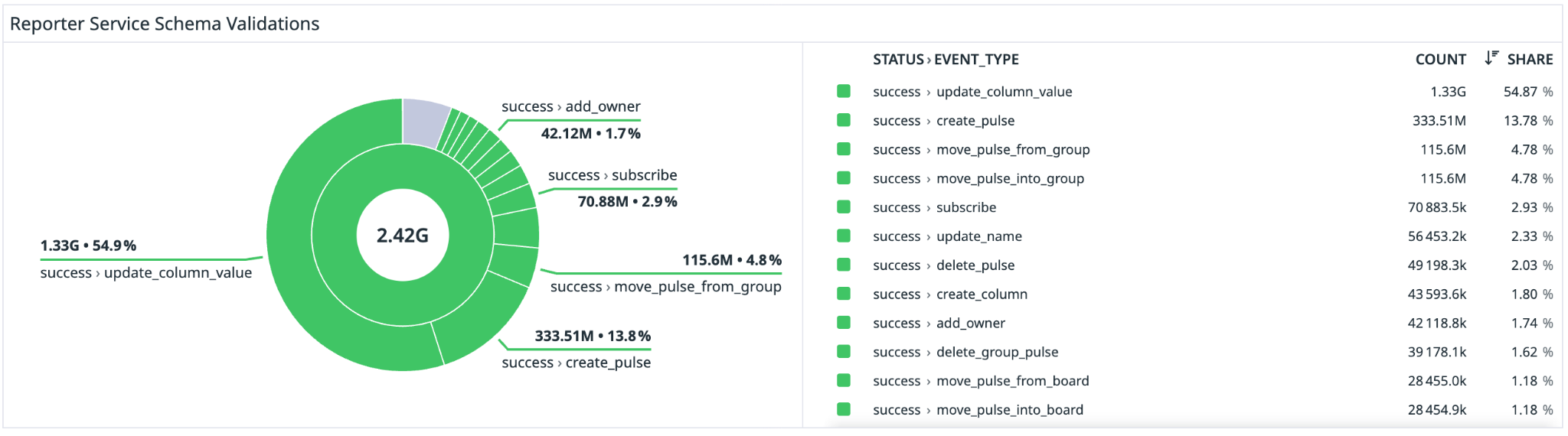
The rule throughout was that production data wins, but backward compatibility was enforced. If we discovered that events contained extra fields or new values, the schema had to learn about them. If we wanted to tighten or simplify a schema, we needed a migration plan for producers and consumers rather than simply rewriting the file.
Centralised Schemas in Git
The schemas themselves live in a dedicated Git repository. The structure is simple: domains at the top level, then services, then event types. For us, this meant schema changes went through the same review process as normal code changes, with dedicated code owners for each schema. It let us attach documentation, rationale, and examples alongside the schemas, and made it trivial to wire schema changes into CI.
Any changes were automatically validated and published separately for TypeScript and Go, using Ajv to validate backwards compatibility.
For TypeScript, we generated interfaces from the JSON Schemas and published them as a package. A service could add a dependency on the library and use it throughout the codebase. Tests could validate sample payloads against both the generated type and the underlying schema, ensuring consistency between compile-time types and runtime contracts.
For Go, we generated struct definitions, whereby a Go service that consumed events from Kafka or SQS could unmarshal into the generated struct and validate against the schema in one go. If the event did not conform, the error could be handled clearly rather than failing later in an application-specific code path.
We derived our types from the schema, and the tooling took care of the rest.
What This Gave Us
The most immediate benefit was discoverability. The collection of schemas became an internal event catalogue. If we wanted to know which events existed in a given domain, who owned them, and what data they carried, we could look in one place rather than trawling through Slack. That matters not just for new services but also for incident response and analytical work.
The second benefit was a reduction in incidents caused by schema drift. As compatibility checks are run in CI, a change that would obviously break existing consumers is rejected at review time rather than after a deployment. Because validation is performed at the point of production, we were able to catch anomalies and malformed events as they happened. We could link them back to a specific producer and code path via our observability.
Furthermore, we now had a path to exposing more schemas externally. Previously, a lot of internal event streams were unsuitable for customer consumption because they had no stability guarantees; any consumer built on them would be at the mercy of invisible internal refactors. With explicit versioned schemas and compatibility rules, we could start treating certain event families as public APIs, document them, and allow third-party integrations to rely on them.
Ultimately, the primary benefit was developer experience. Once we had stable contracts and a catalogue of events, we could build higher-level tooling. The target state was that a developer creating a new microservice or extension could visit an internal console, select the events they cared about, and have a starter project generated with the right subscriptions, types, and validators pre-wired. The underlying transport, be it Sidekiq, Kafka, or anything else, became an implementation detail compared to the shape of the data.
Every Important Event Needs a Schema
None of this relies on exotic technology. JSON Schema, validators like Ajv, Git repositories, and CI pipelines are standard building blocks. The hard part is cultural: deciding that service communication should be contractual, that every important event deserves a schema, that every schema should have an owner, and that breaking changes are not allowed to slip through quietly.


