
How We Scaled Board Item ID Generation at monday.com
As engineers at monday.com, we often find ourselves balancing the speed of our legacy monolith with the scalability needs of a hyper-growth platform. For a long time, our monolith did exactly what it was supposed to: create board items and store them in a single master MySQL database. Simplicity was key, and a simple serial ID column handled identity perfectly.
But as our scale exploded, that single MySQL master became a bottleneck and a single point of failure for creating board items. Every DB hiccup affected monday.com customers’ ability to interact with their boards.
We needed to break item generation out of the monolith to support our transition to a distributed, resilient microservices architecture.
This sounds like a standard microservices refactor, except for one massive constraint: Board Item IDs had to remain integers.
Because so many downstream services and legacy logic relied on the ID being a number, switching to UUIDs wasn’t an option without rewriting half the codebase.
Here is how we solved the “Integer ID” problem in a distributed world.
The Solution: A Centralized ID Generator
We decided to build a dedicated ID Generator Service backed by DynamoDB.
The core idea was simple: instead of a database auto-incrementing a counter for every single row insertion (which locks and bottlenecks), we would have a service that leases “ranges” of IDs to clients.
Architectural Decision: SDK vs. Central Service
Early on, we debated whether to have our client SDKs talk directly to DynamoDB or to put a dedicated service in the middle.
Option A: SDKs talking directly to DynamoDB
- Pros: Lower latency (one less network hop), lower complexity (fewer moving parts)
- Cons:
- Maintenance nightmare: The maintenance burden would be massive. Any change to the generation logic, rate limiting, or caching strategy would require a “monday.com-wide” change. We would have to coordinate SDK updates across hundreds of microservices and wait for every team to deploy.
- Connection & throttling chaos: With hundreds of thousands of pods, direct connection was a non-starter. Thousands of clients simultaneously hitting the same partition key (boards.item) would trigger DynamoDB’s hot partition throttling almost instantly. Furthermore, managing thousands of concurrent HTTP connections to AWS is inefficient and would quickly exhaust API rate limits.
Option B: Centralized ID generation service
- Pros: Agility and encapsulation. By centralizing the logic, we could tune buffer sizes, switch storage backends, or patch bugs in a single deployment without touching the client services. It also served as a “shock absorber” for DynamoDB, smoothing out traffic spikes.
- Cons: Introduced a slight network latency overhead (which we completely eliminated – more on that later on)
We chose Option B (The Service). The ability to evolve our ID generation logic without forcing a company-wide migration was the deciding factor.
Why DynamoDB?
We chose DynamoDB as our persistent layer because, when building the “source of truth” for IDs, you need reliability above all else. DynamoDB gave us:
- Extreme availability: 99.999% uptime SLA for Global Tables.
- Multi-region replication: Crucial for disaster recovery and our future multi-region goals.
- Low latency: Single-digit millisecond latency inside our VPC.
The Data Model
We kept the schema incredibly simple. We only track the lastID allocated for a specific entity type.
- Partition key (entityType): String format: {domain}.{entityType} (e.g., “boards.item”)
- Attribute (lastID): Number. The last allocated ID for this entity.
Atomic Updates
This is the heart of the system. When the service needed to refill its buffer, it performed a single atomic operation against DynamoDB:
SET lastID = if_not_exists(lastID, :min) + :count
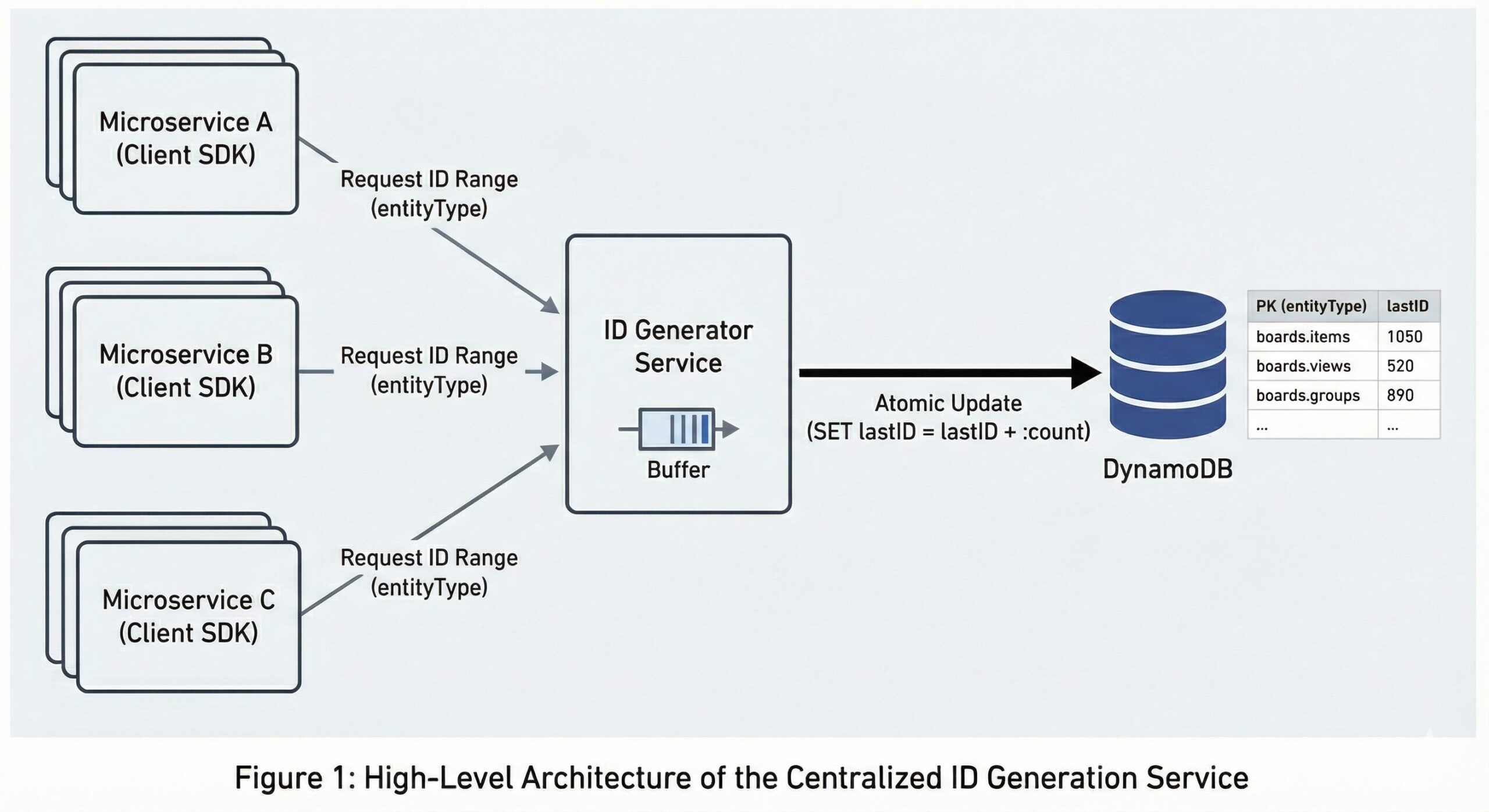
This operation incremented the database counter by :count and returned the new value. If the DB said the new value was 1050 and we asked for 50, we knew we unequivocally owned the range 1001-1050. This guaranteed that no two servers could ever claim the same ID range, even if they requested it at the exact same microsecond.
Optimizing for Performance
The biggest threat when moving from a local database to a network service is latency. In a high-throughput system, adding even 50ms to the critical path isn’t just a noticeable delay—it’s unacceptable. To neutralize this risk, we implemented a double-buffering strategy that effectively eliminates runtime latency.
1. In-Memory Buffering & Eager Loading
It wasn’t just about fetching batches; it was about when we fetch them. We used an eager loading approach so that IDs were pre-allocated and waiting in memory before a request ever arrived.
- The service side: Maintained an in-memory buffer of IDs ready to be served. If availability dropped below 80%, it triggered a background thread to fetch and refill it.
- The client SDK side: When a service started up, it immediately requested a range of IDs (e.g., 1,000 IDs) and stored them in RAM. When a user created a board item, the SDK immediately grabbed an ID from this local pool. There was zero network I/O on the critical path of creating an item. The SDK refilled its pool in the background asynchronously.
2. Handling ID “Waste”
The unavoidable trade-off of eager pre-allocation is waste. Every time a Kubernetes pod grabs 1,000 IDs and restarts, those IDs vanish permanently. While our ID capacity was massive, it was strictly finite (JS Number.MAX_SAFE_INTEGER), meaning a sudden pod crash-loop could silently burn through our runway.
To mitigate this, we implemented strict controls:
- Daily consumption limits: We defined a “sanity limit” on the number of IDs a specific entity can consume per day.
- Observability: We set up alerts on the “Burn Rate” of IDs. If a service starts consuming IDs 50% faster than usual (indicating a potential crash loop where pods start, grab IDs, and die), we get paged immediately.
Rolling Out with Zero Disruption
Generating Board items is a fundamental, high-throughput flow for monday.com customers. We had to make sure all possible risks were mitigated and observed.
1. Stress and Chaos Testing
Before touching production, we used k6 to simulate a massive load on our staging environment. We didn’t just test the “happy path”; we tested rainy day scenarios:
- DynamoDB Outages: We simulated connectivity loss to ensure the local buffers allowed the app to survive short blips.
- Pod Churn: We spun pods up and down rapidly to test the “ID waste” impact.
- Buffer Saturation: We forced high load on a small number of pods to ensure the background refillers could keep up.
2. Shadow Mode with “Fake” Entities
We deployed the ID Generator to production in “Shadow Mode.” The service generated IDs in the background for every item created, but we threw those IDs away and kept using the MySQL ID.
Crucially, we used a fake entity key (e.g., shadow.boards.item) during this phase. This allowed us to stress-test the infrastructure without incrementing the counter on the real boards.item key. This ensured that when we finally went live, we could start with a clean slate and the correct ID sequence.
3. The Gradual Rollout & The “High Water Mark” Problem
Our most dangerous rollout hazard was MySQL’s underlying behavior: inserting a row with a higher ID instantly fast-forwards the table’s auto-increment counter. If our Generator leaped ahead of MySQL’s sequence, the database would silently ‘catch up,’ practically guaranteeing catastrophic ID collisions between the monolith and the new service.
To fix this, we created a 5-billion ID safe zone:
- We manually set the MySQL AUTO_INCREMENT counter 5 billion ahead of the current max.
- We configured the ID Generator to fill the gap strictly below this new ceiling.
Because the new IDs were smaller than the database’s high-water mark, MySQL never moved its pointer. This allowed us to safely fill the gap while we gradually ramped up traffic from 1% to 100%, monitoring latency and consumption rates until the monolith was officially retired.
If You Were Starting Today…
If you are reading this and starting a new architecture from scratch, don’t do what we did.
Unless you have a strict legacy constraint, as we did, UUIDs are the superior choice. They allow you to generate IDs completely offline without a central coordinator or single point of failure.
Specifically, look into UUIDv7.
Standard UUIDs (v4) are completely random. This is great for uniqueness, but terrible for database performance because inserting random keys causes index fragmentation.
UUIDv7 solves this by embedding a timestamp into the UUID. This makes them:
- Sortable: You can order them by time, just like an integer.
- Database Friendly: They are sequentially close to each other, which keeps B-Tree indexes happy and performant.
But, if you are stuck with integers and need to scale, a buffered, DynamoDB-backed generator is a battle-tested way to break free from the monolith.


