
Every Playwright Needs a Director – How AI Agents Replace DOM Scraping with Component-Aware Static Analysis
End-to-end testing has always been a paradox. We rely on it to give us confidence, yet the way we build it is often fragile, expensive, and difficult to scale.
Most modern E2E testing solutions, including AI-powered ones, still operate at the DOM level. They scrape elements, infer intent from rendered HTML, and generate tests based on what the browser happens to show at a specific moment in time. While this approach works, it’s inherently brittle. Minor UI changes break selectors, refactors invalidate assumptions, and test maintenance becomes a constant tax on teams.
Playwright, as a tool, is not the problem. In fact, it’s one of the most powerful E2E frameworks we have. But even the best Playwright needs a director.
Instead of asking Playwright to improvise based on the DOM, we asked a different question:
What if tests were generated from an understanding of the application’s components, structure, and intent – before the browser ever opens?
In this post, I’ll walk through a new approach to building end-to-end testing infrastructure using AI agents, component-aware static analysis, and Playwright as the execution layer. By treating Playwright like an actor following a script – and AI agents as the directors orchestrating each phase – we can generate reliable, scalable E2E tests with a single click.
From DOM Guessing to Directed Testing
Most AI-driven E2E solutions today still start from the same place: the browser.
They observe the DOM, infer intent from rendered HTML, and generate automation code based on what happens to be visible at runtime. While this approach works, it introduces fundamental blind spots:
- The browser has no understanding of business logic
A browser can only see what is rendered, not why it is rendered. Business logic lives in the source code. When AI agents operate purely at the DOM level, they lack context about a component’s purpose, rules, and relationships. - One rendered state ≠ all possible behaviors
Modern applications render components differently based on props, state, permissions, and feature flags. The browser exposes only one permutation at a time, creating a dangerous illusion of coverage. - Feature flags are invisible at the DOM level
From the browser’s perspective, feature flags are already resolved. Alternate flows, experiments, and upcoming functionality simply don’t exist. - No meaningful correlation to application code
Generated selectors and DOM structures rarely map cleanly back to component names or ownership, making tests harder to understand, review, and maintain.
At a deeper level, DOM-based AI testing treats Playwright like an improvising actor reacting to the stage. But reliable end-to-end testing requires a script, an understanding of the story, and a director who knows how all the scenes fit together.
That realization led to a key architectural shift.
Instead of asking Playwright to infer intent at runtime, we moved understanding upstream – into the source code itself – and split the system into two distinct phases:
The Two-Phase Architecture
| Phase | Responsibility | Frequency |
| Phase 1: Setup | Analyze the application’s components, structure, and intent, and build a stable automation foundation | One-time / major refactors |
| Phase 2: Generation & execution | Generate, run, and heal tests deterministically as the code evolves | Continuous / per GitHub trigger |
Playwright remains the execution engine – but it no longer improvises. It performs.
Phase 1: Building the stage (Setup)
Building the foundation, turning source code into structured truth.
Agent #1: The Script Analyst (Component Tree Analyzer)
Goal: Build a component-aware single source of truth for interactable elements.
- The Role: Just as a lead analyst breaks down a script to understand every character’s motivation, this agent identifies every interactable “actor” in your source code.
- How it works: It analyzes microfrontend source code, filtering out noise (tooltips, icons, text-only components) to focus on actual interaction blocks.
- Why this matters: It captures architecture and intent, not just pixels, and sets the stage for handling multiple permutations of the UI.

Example of partial output of the component-tree-analyzer agent
Agent #2: The Stage Manager (data-testid Injector)
Goal: Provide a stable, semantic identification layer for UI elements.
- The role: “Every actor needs a clear mark to stand on.” The Stage Manager ensures that when the Director calls for an action, there is no confusion about which element is being addressed.
- How it works: It processes nodes from the Analyzer. If a data-testid is missing, it adds a context-aware ID (e.g., sprint-settings-close-button) directly into the source code via a PR or local edit.
- Why this matters: It restores a stable locator contract that survives UI refactors and strengthens the link between application code and test code.
Agent #3: The Blocking Coach (Playwright Locator Generator)
Goal: Translate component structures into execution-ready Playwright locators.
- The Role: Deciding exactly where an actor stands and what they touch. Instead of the actor “finding their way” during the live show, the Blocking Coach pre-determines the most efficient path.
- How it works: It analyzes the tree and injects IDs to generate a dedicated locator catalog using a strict priority: data-testid → semantic roles → ARIA labels → text.
- Why this matters: Tests don’t “discover” elements at runtime; they rely on verified, intentional locators from day one.
Agent #4: The Set Designer (Page Object Model Builder)
Goal: Generate a structured Page Object Model (POM) reflecting the application’s architecture.
- The Role: The audience never sees the scaffolding, but the entire performance depends on it. The Set Designer builds the environment where the tests live.
- How it works: It consumes previous outputs to generate code that mirrors the component hierarchy and reuses atomic components from a shared testkit.
- Why this matters: This generates first-class automation infrastructure that developers can read and review, rather than throwaway scripts.
Phase 2: Running the show (Generation & Execution)
Directing the performance, moving from what exists to what should happen.
Agent #5: The Choreographer (Test Planner)
Goal: Turn static structure into meaningful user journeys.
- The Role: The Choreographer decides the sequence of movements that tell the story. They don’t just look at one frame; they plan the entire flow from opening curtain to final bow.
- How it works: It analyzes business logic, state transitions, and conditional paths to determine how flows should progress without relying on DOM recording.
- Why this matters: Flows aren’t limited to a single visible path; edge cases and alternate branches (like feature flags or error states) are naturally included.
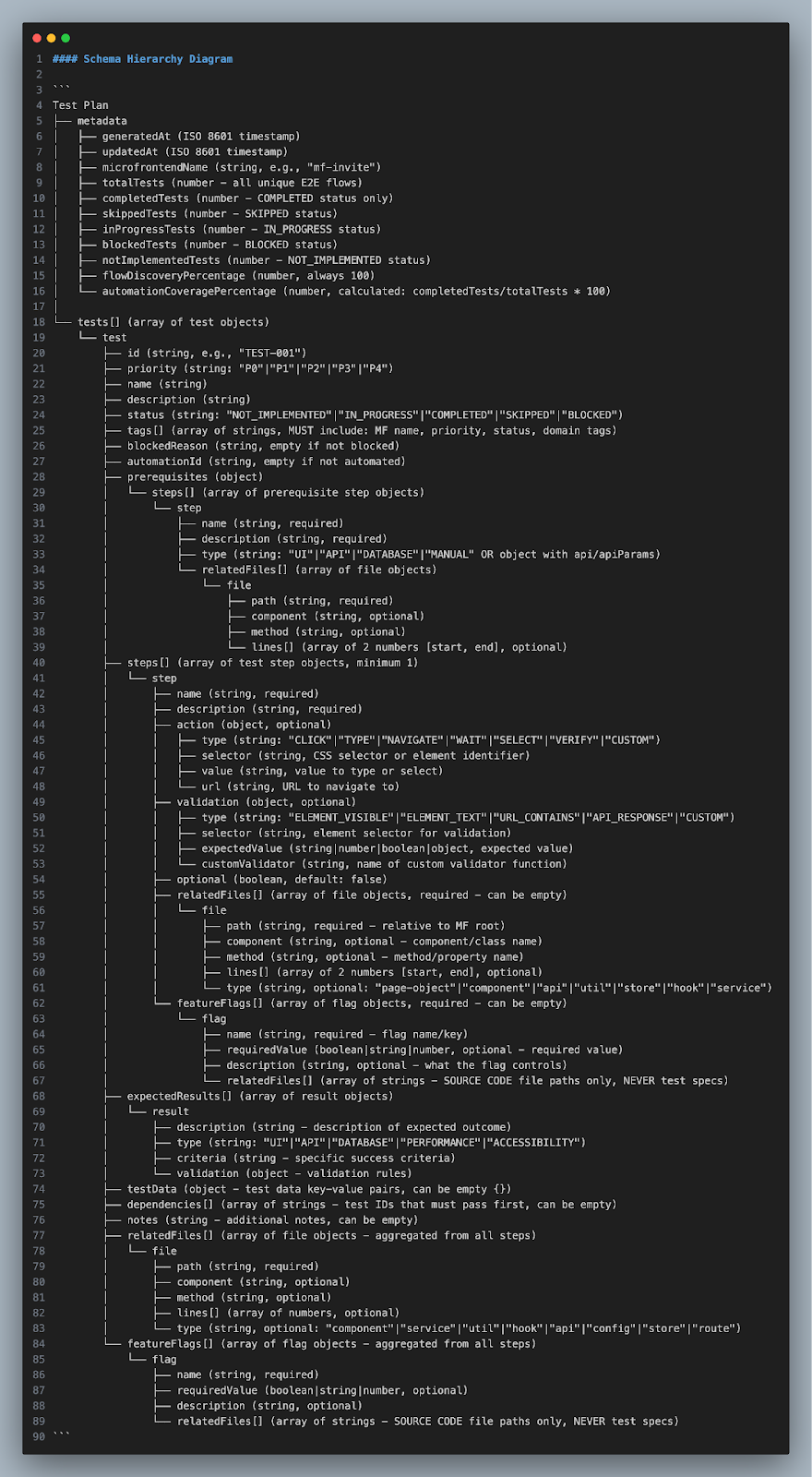
Test plan agent output schema
Agent #6: The Assistant Director (E2E Tests Generator)
Goal: Turn the approved plan into real, executable Playwright tests.
- The Role: “The plan is set. The set is built. Now it’s time to call action.” The Assistant Director ensures the Choreographer’s vision is translated into specific instructions for the performer (Playwright).
- How it works: It maps the Test Planner’s steps to Page Object methods. There is no element discovery at runtime; it strictly executes the script.
- Why this matters: Code is deterministic and readable. Failures point to business logic problems, not “flaky” locator noise.
Agent #7: The Continuity Lead (Tests Healer)
Goal: Validate that tests work and diagnose failures at the correct layer.
- The Role: If an actor misses a line, the Continuity Lead reviews the footage to see if the script needs changing or if the actor simply made a mistake.
- How it works: It executes tests and monitors traces/logs. If a failure occurs, it determines if the issue is test-related (needs a script update) or a real application bug.
- Why this matters: It reasons about intent. It doesn’t blindly “patch” selectors; it understands what the test was meant to verify and keeps the production running smoothly
Closing the Loop
This is no longer test generation. It’s a self-directed, component-aware E2E production system – with Playwright as the performer and AI agents as the crew.
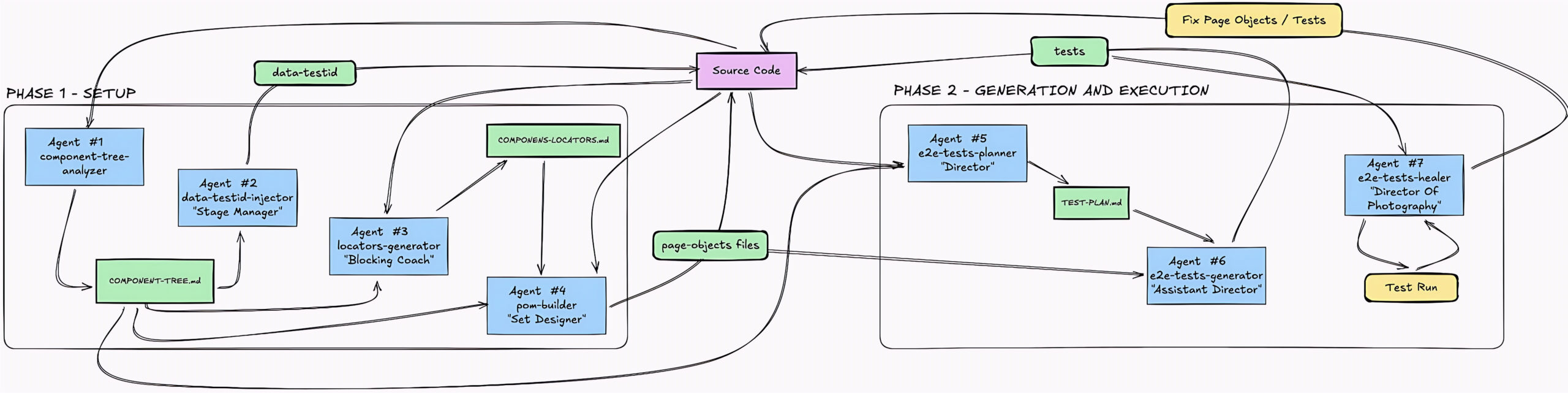
Graphic description of the full agents workflow
The Results: From Zero to Production E2E in Under an Hour
Once the full seven-agent pipeline is in place, the impact becomes immediately visible – not just in speed, but in how teams approach automation.
Time to Value
What traditionally took weeks of manual effort, coordination, and iteration now takes:
- 30-40 minutes for the full initial setup
- One to two days to refine edge cases and validate complex flows
In practice, teams moved from an empty repository to a fully working, component-aware E2E system in under an hour.
Adoption Without Friction
After the pipeline stabilized, adoption happened organically.
Teams were able to:
- Plug the system into existing repositories
- Trigger it in a single click directly from Sphera (our internal developer portal)
- Generate a complete E2E foundation without prior test infrastructure
No long onboarding. No framework rewrites. Teams adopted it after seeing working examples rather than through a formal rollout.
What Actually Changed for Teams
The biggest shift wasn’t just speed – it was where effort was spent.
Teams stopped:
- Writing selectors by hand
- Reverse-engineering DOM structures
- Repairing brittle tests after UI refactors
Instead, they focused on:
- Defining meaningful user flows
- Validating business behavior
- Reviewing generated artifacts as real, maintainable code
Automation stopped being a separate discipline and became part of the system itself.
Why This Scales
Because the setup phase is a one-time investment, teams don’t repeatedly pay the cost of building and maintaining brittle automation.
- Once the foundation exists:
- New tests are generated incrementally
- Changes remain localized to affected components
- Maintenance is driven by source code changes rather than broken runs
This is why the methodology scaled quickly across teams – not because responsibility disappeared, but because unnecessary manual work did.
Summary
End-to-end testing doesn’t have to be brittle, reactive, or expensive to maintain. By moving upstream – from DOM-based observation to component-aware static analysis – we can give Playwright what it actually needs: structure, intent, and a script to follow.
The seven-agent pipeline turns E2E testing from a browser-driven guessing game into a deterministic, inspectable, and repairable production system. Together, they ensure:
- Tests reflect application architecture.
- Coverage is intentional.
- Failures are diagnosable.
- Automation scales with the codebase.
What Comes Next: Continuous Test Intelligence
The next phase introduces agents that monitor Git-level code changes.
- Proactive Analysis: Agents scan PRs to see if changes break existing tests or require new ones.
- Human-in-the-Loop: Suggestions are surfaced as PR comments, allowing developers to approve regenerated tests before they even merge.
With this final layer in place, E2E testing becomes:- self-aware – able to detect when it may no longer be valid,
- self-adapting – evolving as the application evolves,
- but still developer-owned – every change is reviewed and intentional.
At that point, tests are no longer static artifacts.
They become living systems, directed by architecture, guided by intent, and executed reliably by Playwright.
If Playwright is the show, this is how you stop improvising and start directing it as the script keeps evolving.


