
5 ways to get better at real-time error monitoring
How we took our real-time error monitoring to the next level with Sentry.io.
As any organization grows, it becomes more difficult to stay on top of performance and quality issues.
A few months ago, we decided to challenge our real-time error tracking and management process so we could design a solution that can handle our rapidly increasing scale. The results of our research led us to adopt a new strategy and a new tool, Sentry.io. We have learned a lot along the way — we hope these lessons will help you, too.
Our challenge at monday.com
At Monday.com, the web client is at the heart of the product, with more than 1.2M monthly users and more than 1M collaborative actions per hour. We make it a mission to be a place that you love coming back to, therefore we are committed to making our web client experience the best in its class.
At the same time, we love to move fast and deliver new features to our users a few times per day, with 8 automatic deployments running at the top of every hour and with 150 engineers pushing new code.
In such a dynamic and fast-paced environment, it is a given that we must stay vigilant to closely monitor our web application experience – success rates, performance, usability, and more— but how do we do it?
Read on to learn more.
Finding the right tool
As we set out to improve error tracking, our error monitoring stack was based on SaaS we already used and a few internal products we created to tailor this service to our requirements. When we challenged this process, we searched for a solution that could replace it all with a one-stop-shop for all platforms and needs.
In addition to supporting the languages and frameworks we use, the following were our top requirements for this new error tracking solution:
- Jump between services seamlessly – as we grow and our architecture becomes more distributed, more services will be involved in each flow. Our goal is to keep the error tracking process simple, and to have visibility into the entire flow for each error in the same place.
- Release management – with more than 150 engineers and automatic deployments running every hour, we searched for a solution that would allow us to easily see the status of a release, engineers involved and relevant errors.
- Customized error grouping logic – Previously, we had received numerous false alarms. We searched for a solution that allowed us to customize grouping of errors for better identification of new issues.
Keeping these requirements in mind, monday.com integrated Sentry.io into its services to achieve this goal. Sentry.io supports all the platforms in our stack and allows easy correlation between them. Sentry.io excels in all other aspects of error tracking, and moreover, provides the option to customize everything to fit your needs, which is exactly what we were looking for.
In the next section, we’ve used the lessons we learned to create a list of best practices for you and your teams when it comes to handling errors.
5 ways to optimize your error tracking and handling process
1. Enrich your errors with distinctive identifiers
By adding valuable identifiers to an error, you can gain a better understanding of the scope and impact of the error.
Each error is created with default identifiers, however our team enriches each with information that is relevant to our app and helps us zoom in faster and more effectively. Here are a few examples:
- Feature flags
Feature flags are a common way to control the release process of new changes. Adding this information to errors lets us easily identify which feature groups were affected by the error.
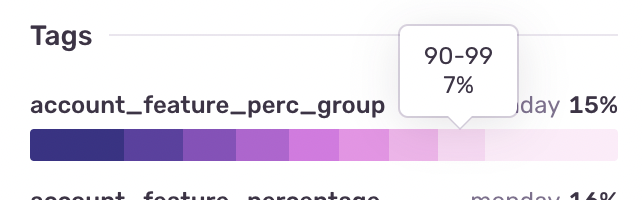
- Tier type
Classify the affected users by monday tier type to better understand the scope and related services.

- Last action
In order to scope the flow that leads to an error, we store on each error the last action that occurred right before the error.
In the example below you can see this error is usually triggered right after an attempt to delete a column:

2. Build a meaningful timeline
By creating a timeline of the actions that led to an error, you can reduce the time required to resolve it.
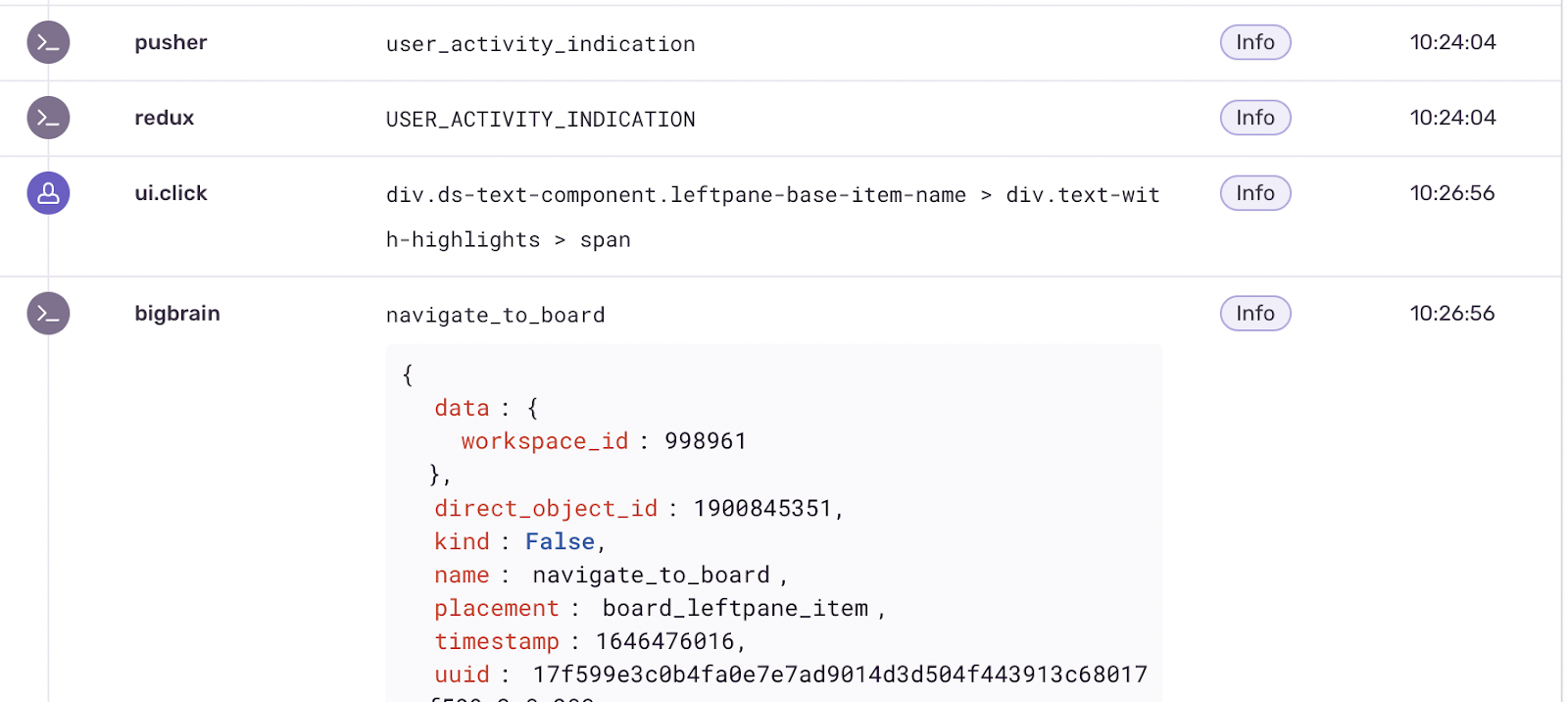
While the default timeline is great, each application has its own logic, so we decided to go the extra mile and add the custom events we need for an in-depth investigation. Here are some examples of the custom events we added:
- Analytics events: The analytics events that we use to measure how users interact with the system were the key to success in the enriching process. Today, we have an event for every interaction, and by embedding those events into our error timeline, we are able to view a full timeline of exactly what happened leading up to the error.
- Redux actions: Due to our reliance on React and Redux, we can also use Redux actions to enrich our errors with additional tags to each error showing the last redux event fired before the action. This helps identify if an error is related to a specific Redux action and allows us to fix it on the spot.
- Last websocket events pushed: Like many modern apps, monday.com heavily relies on websockets for live updates. Since these live updates are a critical part of what our users are experiencing, we added each such update to our timeline as well.
And if you want to see it all together, here is a timeline for example –
3. Implement a generic ErrorComponent to avoid uncaught errors
Seeing the white screen of death is one of the worst things that can happen to a user.
We use a special error component for uncaught errors and to show visual explanations of what went wrong. We also keep the propagation of these errors to the smallest scope possible, so if something happens to a small button in our app, it won’t cause the whole app to crash.
Our existing ErrorComponent has been integrated with Sentry.io, allowing us to enrich every event of “ErrorComponent” with the stacktrace and the original component that caused the error. We now have a dashboard where we can aggregate these errors so that we can always keep an eye on our uncaught errors and prioritize our efforts accordingly.

4. Correlate your client and server errors
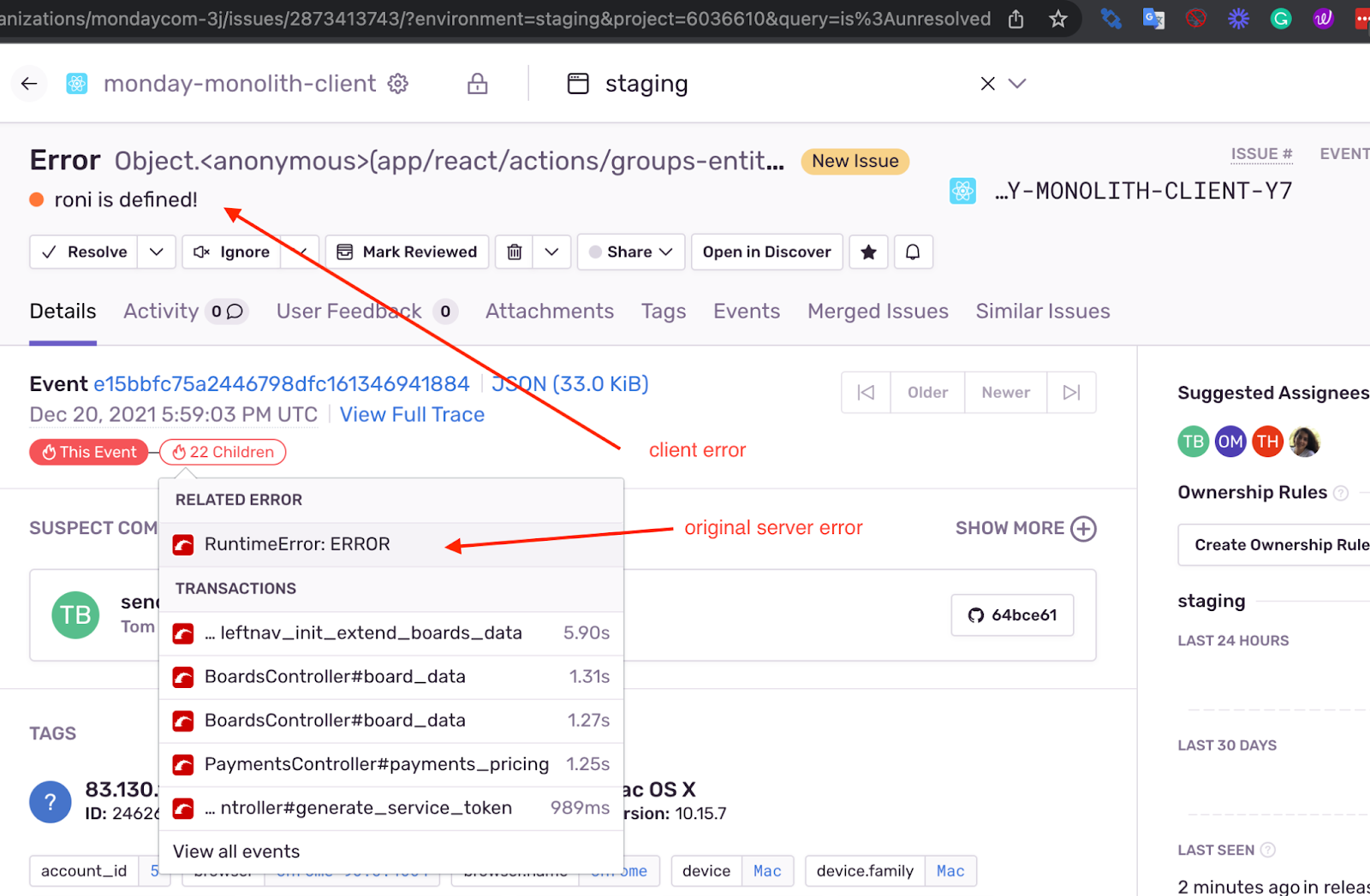
The more complex our system becomes, with more microservices, routes, and integrations, the more important it is to correlate between sessions, because even if each request worked well on its own, when things get to production, the integration of services has the potential for problems.
Sentry.io’s auto-correlation of client and server errors was one of the reasons we chose to work with the platform. When both the client and the server use Sentry.io, by automatically correlating errors we can jump between a client error and the specific server error that caused it without any extra effort.
5. Setup essential alerts
Monitoring the production environment is always a challenge with many deployments from our side, third party integrations, and cloud resources we depend on. Because of this, it is important to stay one step ahead to provide the quality we demand for our users.
As a team, we have two key alerts that are most meaningful to our day-to-day work :
- Notification when a new issue is created: This is our heartbeat on newly created issues, making sure they are assigned to the right team. To prevent alert fatigue, we have adjusted the threshold on those alerts so only high impact alerts will trigger.
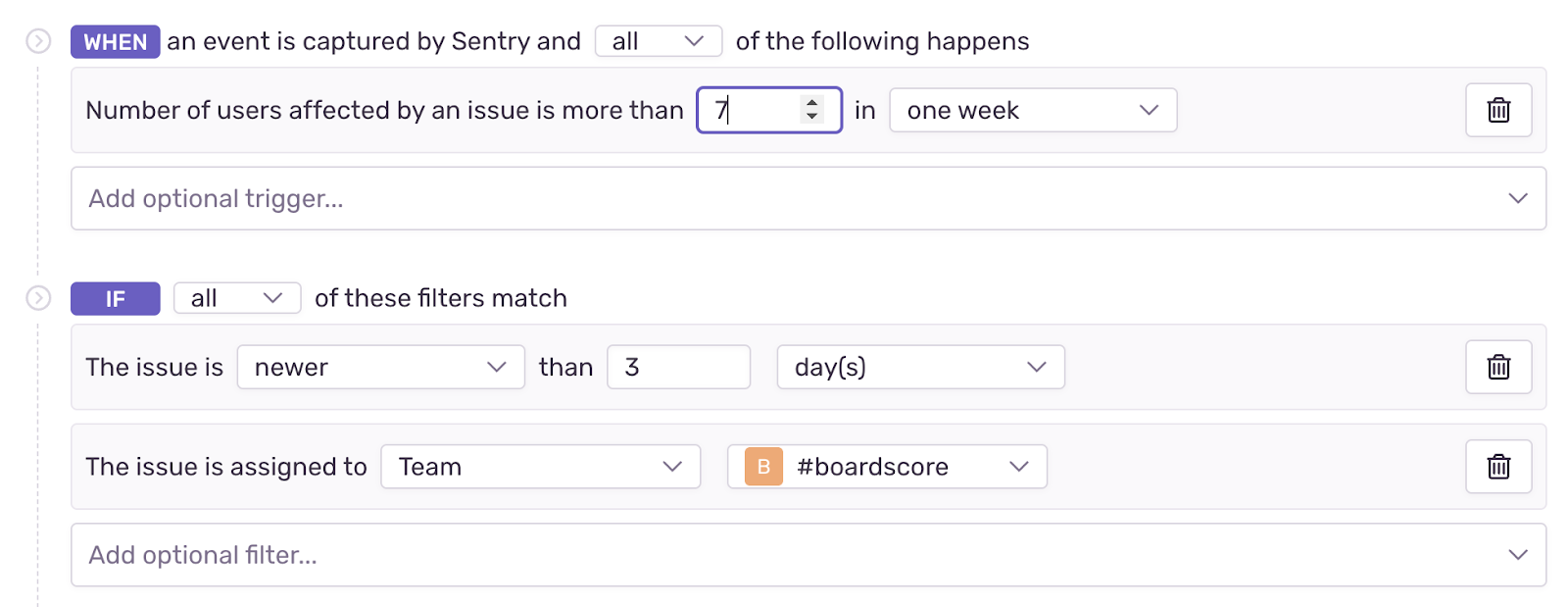
With the above configuration we prevent known issues from resurfacing and focus notification only on new issues with real user’s impact.
- Spike alerts: We use spike alerts to fastly detect a drastic increase in the number of errors. It allows us to reduce the time to detect a critical component which is misfunctioning.
We use these alerts to ensure errors are handled with the right priority and are assigned to the relevant teams. Unassigned alerts are usually not treated with the appropriate attention, that’s why it’s important to assign the error to the most relevant team and person.
To accomplish this, we set code owners in GIT, integrated it with Sentry.io, and along with the alerts, we always notify the relevant person when a new error is caught!
For example, our kubernetes configuration will be owned by our Infra team, but changes in the core of our client monolith such as the webworker infrastructure, will be sent to our client foundations team.
Challenge your process, fix more errors
We hope you’ll find these tips and insights useful and that they help increase the reliability and stability of your production environment.
If you share our passion for fixing errors, feel free to contact us and tell us what you think! Or if you just have a question about what we do and want more in-depth information, we’d be glad to help with that as well!


